

목록전체 글 (353)
printf("ho_tari\n");
 ep.30 딥러닝개론4
ep.30 딥러닝개론4
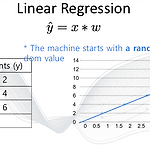
2024.8.19 import numpy as npimport matplotlib.pyplot as pltx_data = [1.0, 2.0, 3.0]y_data = [2.0, 4.0, 6.0]w = 1.0def forward(x): return x * wdef loss(x, y): y_pred = forward(x) return (y_pred - y) * (y_pred - y)w_list = []mse_list = []for w in np.arange(0.0, 4.1, 0.1): print("w=", w) l_sum = 0 for x_val, y_val in zip(x_data, y_data): y_pred_val = forward(x_val) l = loss(x_val, y_val..
 ep.29 딥러닝개론3
ep.29 딥러닝개론3
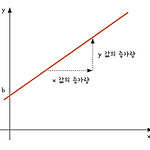
2024.8.16 일차 함수, 기울기와 y 절편▪ 함수란 두 집합 사이의 관계를 설명하는 수학 개념▪ 변수 x와 y가 있을 때, x가 변하면 이에 따라 y는 어떤 규칙으로 변하는지 나타냄▪ 보통 함수를 나타낼 때는 function의 f와 변수 x를 사용해 y =f(x)라고 표시▪ 일차 함수는 y가 x에 관한 일차식으로 표현된 경우를 의미▪ 예를 들어 다음과 같은 함수식으로 나타낼 수 있음▪ x가 일차인 형태이며 x가 일차로 남으려면 a는 0이 아니어야 함▪ 일차 함수식 y = ax + b에서 a는 기울기, b는 절편이라고 함▪ 기울기는 기울어진 정도를 의미하는데, 그림 3-1에서 x 값이 증가할 때 y 값이 어느 정도 증가하는지에 따라 그래프의 기울기 a가 정해짐▪ 절편은 그래프가 축과 만나는 지점을 의..
 ep.28 딥러닝개론2
ep.28 딥러닝개론2
2024.8.14 브로드캐스팅Numpy에서 차원이 맞지 않은 객체끼리 연산1차원 배열 x 를 확장슬라이싱을 통해 여러 값 가져오기• 참고로 리스트 슬라이싱을 할 때 칼럼은 안됨• row에 대한 슬라이싱은 df['a':'d’]• 대신 loc, iloc을 주로 사용 머신러닝 실습 (타이타닉호 분석)• 타이타닉호의 생존자와 관련된 변수의 상관관계를 찾아봄• 생존과 가장 상관도가 높은 변수는 무엇인지 분석• 상관 분석을 위해 피어슨 상관 계수를 사용• 변수 간의 상관관계는 시각화하여 분석상관 분석• 두 변수가 어떤 선형적 관계에 있는지를 분석하는 방법• 두 변수는 서로 독립적이거나 상관된 관계일 수 있는데, 두 변수의 관계의 강도를 상관관계 라고함• 상관 분석에서는 상관관계의 정도를 나타내는 단위로 모상관 계수..
 ep.27 딥러닝개론1
ep.27 딥러닝개론1
2024.8.13 빅데이터 출현 배경"BIG DATA != 대용량 자료"가 아니다.- 조직의 내외부에 존재하는 다양한 형태의 데이터를 수집, 처리, 저장하여- 복적에 맞게 -북석함으로써 해당 분야의 필요 지식을 추출하고- 이를 조직의 전략적 의사결정에 활용하거나- 이를 시스템화하여 상시적으로 생산성향상에 활용하거나- 새로운 비즈니스 모델의 창출에 활용하고자 하는 패러다임1. 3V -> 4V -> 5V2. 처리, 분석 기술적 변화까지 포함3. 인재, 조직 변화 Digital Transformation(DT, DX)디지털적인 모든 것(All Things Digital)으로 인해 발생하는 다양한 변화에 대하여 디지털 기반으로 기업의 조직, 시스템 프로세스, 비즈니스 모델, 기업문화 커뮤니케이션등을 총망라해서 ..
 ep.26 파이썬 기반 서버프로그램 구현(Git&Docker 활용)
ep.26 파이썬 기반 서버프로그램 구현(Git&Docker 활용)
2024.8.12 Mysql 외부접속 설정디비 접속 계정 생성시작전 root 계정 전환sudo su –nano /etc/mysql/mysql.conf.d/mysqld.cnf 실행한다주석해제 진행저장 ctrl+x → Y 저장방화벽 포트가 비활성화 라면 활성화 적용sudo ufw enablesystemctl restart mysql (데몬 재구동 진행)Mysql 재구동 확인• create user ‘tester2’@’%’ identified by ‘0000’ ; 접속 계정생성• Grant all privileges on *.* to ‘tester2’@’%’; 권한• Flush privileges;• Exit ;• Systemctl restart mysql 재구동• 계정 새로 생성하면서 권한 적용 필• Roo..
 ep.25 DBMS 연동 프로그램 구축
ep.25 DBMS 연동 프로그램 구축
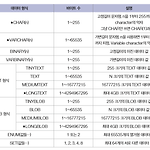
2024.8.9 MySQL에서 지원하는 데이터 형식의 종류◦ 문자 데이터 형식◦ 날짜와 시간 데이터 형식◦ 기타 데이터 형식◦ LONGTEXT, LONGBLOB⚫ LOB(Large Object, 대량의 데이터)을 저장하기 위해 LONGTEXT, LONGBLOB 데이터 형식 지원⚫ 지원되는 데이터 크기는 약 4GB의 파일을 하나의 데이터로 저장 가능변수의 사용◦ Workbench를 재시작할 때까지는 계속 유지, Workbench를 닫았다가 재시작하면 소멸데이터 형식과 형 변환◦ 데이터 형식 변환 함수⚫ CAST( ), CONVERT( ) 함수를 가장 일반적으로 사용⚫ 데이터 형식 중에서 가능한 것은 BINARY, CHAR, DATE, DATETIME, DECIMAL, JSON, SIGNED INTEGER,..
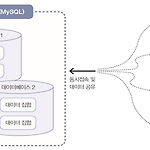 ep.24 DBMS 개요, MySQL 소개
ep.24 DBMS 개요, MySQL 소개
2024.8.8 ◦ 데이터베이스⚫ ‘데이터의 집합’⚫ 여러 명의 사용자나 응용프로그램이 공유하는 데이터들⚫ 동시에 접근 가능해야⚫ 데이터의 저장 공간’ 자체◦ DBMS⚫ 데이터베이스를 관리·운영하는 역할DBMS 개념도DB/DBMS의 특징◦ 데이터의 무결성 (Integrity)⚫ 데이터베이스 안의 데이터는 오류가 없어야⚫ 제약 조건(Constrain)이라는 특성을 가짐◦ 데이터의 독립성⚫ 데이터베이스 크기 변경하거나 데이터 파일의 저장소 변경시 기존에 작성된 응용프로그램은 전혀 영향을 받지 않아야◦ 보안⚫ 데이터베이스 안의 데이터에 데이터를 소유한 사람이나 데이터에 접근이 허가된 사람만 접근할 수 있어야⚫ 접근할 때도 사용자의 계정에 따라서 다른 권한 가짐◦ 데이터 중복의 최소화⚫ 동일한 데이터가 여러 개..