
printf("ho_tari\n");
ep.28 딥러닝개론2 본문
2024.8.14


브로드캐스팅
Numpy에서 차원이 맞지 않은 객체끼리 연산
1차원 배열 x 를 확장
슬라이싱을 통해 여러 값 가져오기
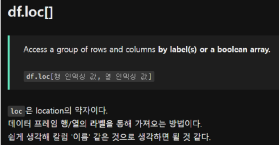
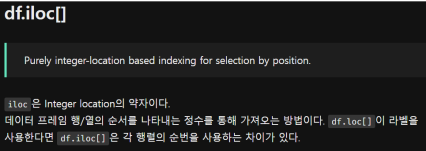
• 참고로 리스트 슬라이싱을 할 때 칼럼은 안됨
• row에 대한 슬라이싱은 df['a':'d’]
• 대신 loc, iloc을 주로 사용


머신러닝 실습 (타이타닉호 분석)

• 타이타닉호의 생존자와 관련된 변수의 상관관계를 찾아봄
• 생존과 가장 상관도가 높은 변수는 무엇인지 분석
• 상관 분석을 위해 피어슨 상관 계수를 사용
• 변수 간의 상관관계는 시각화하여 분석
상관 분석
• 두 변수가 어떤 선형적 관계에 있는지를 분석하는 방법
• 두 변수는 서로 독립적이거나 상관된 관계일 수 있는데, 두 변수의 관계의 강도를 상관관계 라고함
• 상관 분석에서는 상관관계의 정도를 나타내는 단위로 모상관 계수 ρ를 사용
• 상관 계수는 두 변수가 연관된 정도를 나타낼 뿐 인과 관계를 설명하지 않으므로 정확한 예측치를 계산할 수는 없음
단순 상관 분석
• 두 변수가 어느 정도 강한 관계에 있는지 측정
다중 상관 분석
• 세 개 이상의 변수 간 관계의 강도를 측정
• 편상관 분석: 다른 변수와의 관계를 고정하고 두 변수 간 관계의 강도를 나타내는 것
상관 계수 ρ
• 변수 간 관계의 정도(0~1)와 방향(+, -)을 하나의 수치로 요약해주는 지수로 -1에서 +1 사이의 값을 가짐
• 상관 계수가 +이면 양의 상관관계이며 한 변수가 증가하면 다른 변수도 증가
• 상관 계수가 –이면 음의 상관관계이며 한 변수가 증가할 때 다른 변수는 감소
• 0.0 ~ 0.2: 상관관계가 거의 없음
• 0.2 ~ 0.4: 약한 상관관계가 있음
• 0.4 ~ 0.6: 상관관계가 있음
• 0.6 ~ 0.8: 강한 상관관계가 있음
• 0.8 ~ 1.0: 매우 강한 상관관계가 있음
• 데이터 수집
import seaborn as sns
import pandas as pd
titanic = sns.load_dataset("titanic")
titanic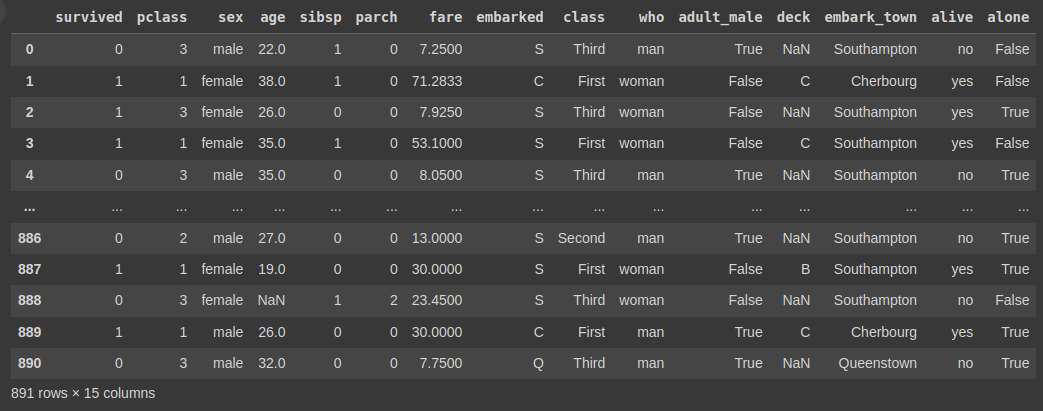
• 데이터 준비
titanic.isnull().sum()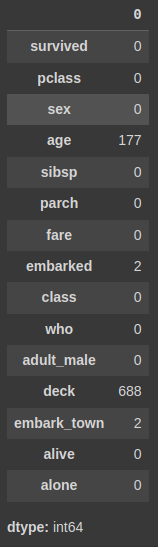
• 데이터 탐색
1. 데이터의 기본 정보 탐색하기
titanic.info()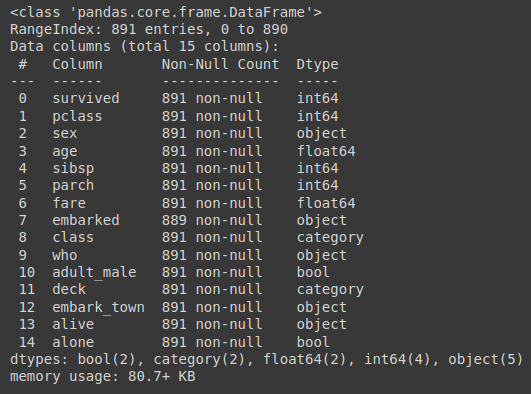
2. 차트를 그려 데이터를 시각적으로 탐색하기
import matplotlib.pyplot as plt
f,ax = plt.subplots(1, 2, figsize = (10, 5))
titanic['survived'][titanic['sex'] == 'male'].value_counts().plot.pie(explode = [0, 0.1], autopct = '%1.1f%%', ax = ax[0], shadow = True)
titanic['survived'][titanic['sex'] == 'female'].value_counts().plot.pie(explode = [0, 0.1], autopct = '%1.1f%%', ax = ax[1], shadow = True)
ax[0].set_title("Survived (Male)")
ax[1].set_title("Survived (Female)")
plt.show()
남자 승객의 생존율: 18.9%
여자 승객의 생존율 74.2%
3. 등급별 생존자 수를 차트로 나타내기
sns.countplot(x = 'pclass', hue = 'survived', data = titanic)
plt.title("Pclass vs Survived")
plt.show()
• 데이터 모델링
1. 상관 분석을 위한 상관 계수 구하고 저장하기
titanic_corr = titanic.corr(method = 'pearson', numeric_only = True)
titanic_corr
2. 상관 계수 확인하기
• 남자 성인(adult_male): 생존(survived)과 음의 상관관계
• 객실 등급(pclass): 음의 상관
• 관계, 객실 요금fare은 양의 상관관계
• 동행 없이 혼자 탑승한 경우(alone): 생존율이 떨어진다는 상관관계
3. 특정 변수 사이의 상관 계수 구하기
titanic['survived'].corr(titanic['adult_male'])
titanic['survived'].corr(titanic['fare'])
# 01행 survived와 adult_male 변수 사이의 상관 계수를 구함
# 02행 survived와 fare 변수 사이의 상관 계수를 구함

• 결과 시각화
1. 산점도로 상관 분석 시각화하기
sns.pairplot(titanic, hue = 'survived')
plt.show()
2. 두 변수의 상관관계 시각화하기
sns.catplot(x = 'pclass', y = 'survived', hue = 'sex', data = titanic, kind = 'point')
plt.show()
3. 변수 사이의 상관 계수를 히트맵으로 시각화하기
def category_age(x):
if x<10:
return 0
elif x<20:
return 1
elif x<30:
return 2
elif x<40:
return 3
elif x<50:
return 4
elif x<60:
return 5
elif x<70:
return 6
else:
return 7
titanic['age2'] = titanic['age'].apply(category_age)
titanic['sex'] = titanic['sex'].map({'male':1, 'female':0})
titanic['family'] = titanic['sibsp'] + titanic['parch'] + 1
heatmap_data = titanic[['survived', 'sex', 'age2', 'family', 'pclass', 'fare']]
colormap = plt.cm.RdBu
sns.heatmap(heatmap_data.astype(float).corr(), linewidths = 0.1, vmax = 1.0, square = True, cmap = colormap, linecolor = 'white', annot = True, annot_kws = {"size":10})
plt.show()
다중 분류 문제 해결하기
import pandas as pd
!git clone https://github.com/taehojo/data.git
df = pd.read_csv('./data/iris3.csv')
df.head()
import seaborn as sns
import matplotlib.pyplot as plt
sns.pairplot(df, hue = 'species')
plt.show()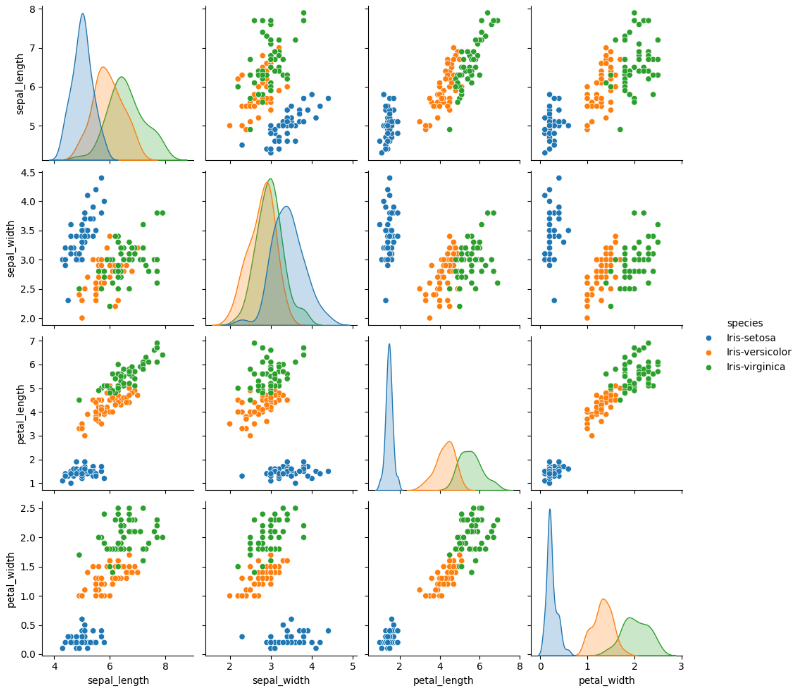
원-핫 인코딩
X = df.iloc[:, 0:4]
y = df.iloc[:, 4]
print(X[0:5])
print(y[0:5])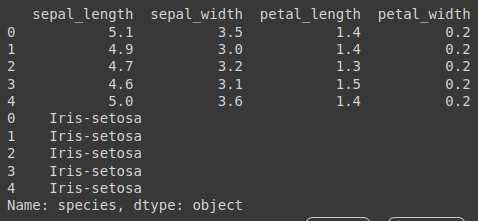
y = pd.get_dummies(y)
print(y[0:5])
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
model.add(Dense(12, input_dim=4, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(3, activation='softmax'))
model.summary()
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(X, y, epochs=50, batch_size=5)Epoch 1/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 2s 2ms/step - accuracy: 0.4194 - loss: 1.1439
Epoch 2/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.3228 - loss: 1.1089
Epoch 3/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.2708 - loss: 1.0804
Epoch 4/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.5251 - loss: 0.9992
Epoch 5/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.6940 - loss: 0.9522
Epoch 6/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.6794 - loss: 0.9187
Epoch 7/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.6315 - loss: 0.9008
Epoch 8/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.6668 - loss: 0.8338
Epoch 9/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - accuracy: 0.6268 - loss: 0.7921
Epoch 10/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - accuracy: 0.6737 - loss: 0.7067
Epoch 11/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - accuracy: 0.7349 - loss: 0.6073
Epoch 12/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - accuracy: 0.7881 - loss: 0.5668
Epoch 13/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.8228 - loss: 0.5368
Epoch 14/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.8444 - loss: 0.4895
Epoch 15/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.9788 - loss: 0.4644
Epoch 16/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.9165 - loss: 0.3862
Epoch 17/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.9453 - loss: 0.3904
Epoch 18/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - accuracy: 0.9234 - loss: 0.3447
Epoch 19/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.9793 - loss: 0.2999
Epoch 20/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.9926 - loss: 0.2892
Epoch 21/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.9567 - loss: 0.2889
Epoch 22/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.9358 - loss: 0.2979
Epoch 23/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.9454 - loss: 0.2941
Epoch 24/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.9893 - loss: 0.2481
Epoch 25/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.9794 - loss: 0.2658
Epoch 26/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - accuracy: 0.9799 - loss: 0.2123
Epoch 27/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9621 - loss: 0.2309
Epoch 28/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9891 - loss: 0.2072
Epoch 29/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - accuracy: 0.9873 - loss: 0.2001
Epoch 30/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - accuracy: 0.9473 - loss: 0.2261
Epoch 31/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - accuracy: 0.9406 - loss: 0.2021
Epoch 32/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - accuracy: 0.9736 - loss: 0.1855
Epoch 33/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9629 - loss: 0.1746
Epoch 34/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - accuracy: 0.9791 - loss: 0.1751
Epoch 35/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - accuracy: 0.9470 - loss: 0.1876
Epoch 36/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - accuracy: 0.9806 - loss: 0.1365
Epoch 37/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - accuracy: 0.9827 - loss: 0.1386
Epoch 38/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - accuracy: 0.9461 - loss: 0.1742
Epoch 39/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9689 - loss: 0.1654
Epoch 40/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9836 - loss: 0.1372
Epoch 41/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - accuracy: 0.9880 - loss: 0.1478
Epoch 42/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - accuracy: 0.9673 - loss: 0.1315
Epoch 43/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - accuracy: 0.9898 - loss: 0.1282
Epoch 44/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9746 - loss: 0.1375
Epoch 45/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - accuracy: 0.9965 - loss: 0.1003
Epoch 46/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9776 - loss: 0.1237
Epoch 47/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9730 - loss: 0.1249
Epoch 48/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9766 - loss: 0.1251
Epoch 49/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - accuracy: 0.9702 - loss: 0.1149
Epoch 50/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - accuracy: 0.9826 - loss: 0.1106
판다스를 활용한 데이터 조사
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
!git clone https://github.com/taehojo/data.git
df = pd.read_csv('./data/pima-indians-diabetes3.csv')
df.head(5)
df["diabetes"].value_counts()
'(두산로보틱스) ROKEY 부트 캠프 > Computer Vision 교육' 카테고리의 다른 글
| ep.32 딥러닝개론6 (0) | 2024.08.21 |
|---|---|
| ep.31 딥러닝개론5 (0) | 2024.08.20 |
| ep.30 딥러닝개론4 (0) | 2024.08.19 |
| ep.29 딥러닝개론3 (0) | 2024.08.16 |
| ep.27 딥러닝개론1 (0) | 2024.08.13 |



