

printf("ho_tari\n");
15일차 본문
2025.05.09
Pytorch 및 필요한 라이브러리 설치하기
Anaconda3 내 설정만으로 PyTorch GPU 환경을 설정하는 방법
- conda 업데이트
- conda update -n base -c defaults conda
- 가상환경 생성 (torch-gpu로 생성, 필요하면 이름 변경)
- conda create -n torch-gpu python=3.10
- conda activate torch-gpu
- CUDA 11.8 / CuDNN 8.9.7 설치
- conda install -c conda-forge cudatoolkit=11.8 cudnn=8.9.7 ( or conda-forge와 defaults 채널에서는 cudatoolkit=12.8이 제공되지 않음)
- PyTorch 2.3.0 설치
- conda install pytorch==2.3.0 torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
- 커널 생성
- pip install ipykernel
- python -m ipykernel install --user --name=torch-gpu
- 설치 확인
Object Detection
1. 객체 탐지 (Object Detection)
- 객체 탐지는 컴퓨터 비전과 이미지 처리와 관련된 컴퓨터 기술로써 디지털 이미지와 비디오를 특정한 계열의 시멘틱 객체 인스턴스를 감지하는 일을 다룬다
- 각 객체 범주의 모든 인스턴스의 위치와 배율을 나타내는 축 정렬 경계 상자와 함께 이미지에 있는 객체 범주 목록 생성
- 한 이미지에서 여러 객체와 그 경계 상자(bounding box)를 탐지(여러 객체를 분류하고 위치를 추정하는 방법)
- 객체 탐지 알고리즘은 일반적으로 이미지를 입력으로 받고, 경계 상자와 객체 클래스 리스트를 출력
- 경계 상자에 대해 그에 대응하는 예측 클래스와 클래스의 신뢰도(confidence)를 출력
Applications
- 자율 주행 자동차에서 다른 자동차와 보행자를 찾을 때
- 의료 분야에서 방사선 사진을 사용해 종양이나 위험한 조직을 찾을 때
- 제조업에서 조립 로봇이 제품을 조립하거나 수리할 때
- 보안 산업에서 위협을 탐지하거나 사람 수를 셀 때
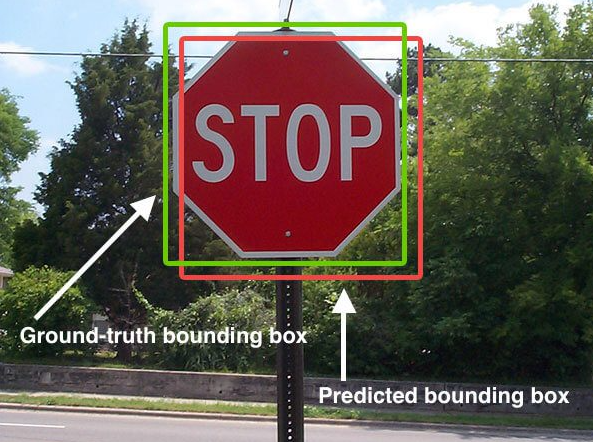
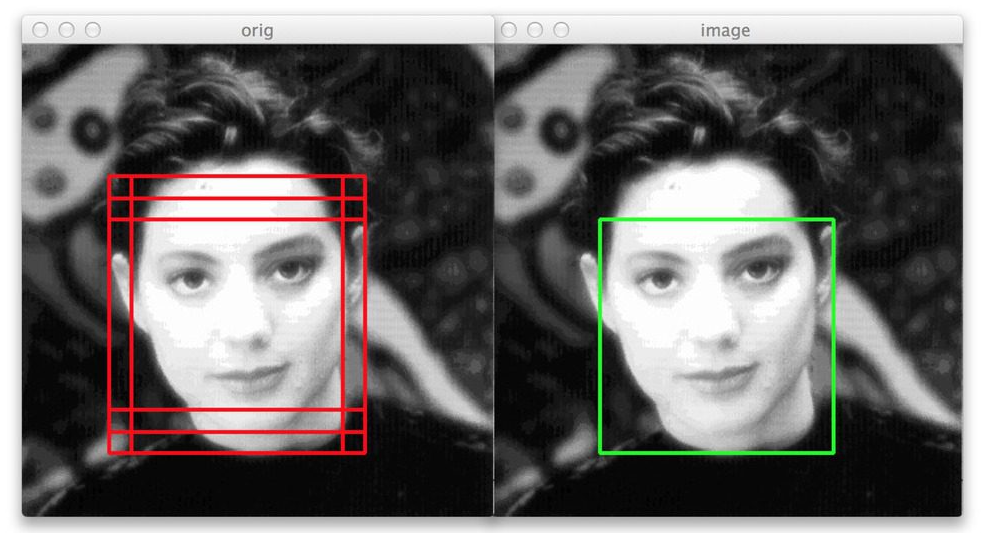
1) Bounding Box
- 이미지에서 하나의 객체 전체를 포함하는 가장 작은 직사각형

2) IOU (Intersection Over Union)
- 실측값(Ground Truth)과 모델이 예측한 값이 얼마나 겹치는지를 나타내는 지표, 0~1 사이
- 예측 Bounding Box와 실제 Ground Truth가 겹치는 부분/예측 Bounding Box와 Ground Truth 겹치는 부분, 즉 두 집합의 교집합/합집합
- Object 영역을 얼마나 정확하게 찾는지 판단. IOU가 0.5 이상이면 2/3 정도 겹치는 정도로 이 정도면 예측을 성공했다고 할 수 있음
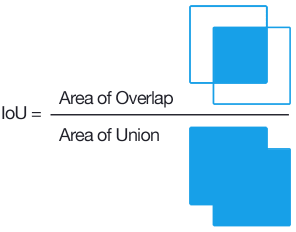
- IOU가 높을수록 잘 예측한 모델
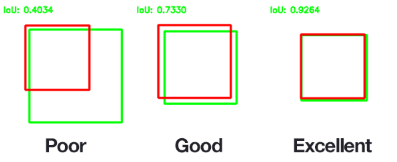
- 예시
3) NMS (Non-Maximum Suppression, 비최댓값 억제)
- 다수의 중복된 예측을 제거하여 최종적으로 하나의 예측만 남기는 과정
- 확률이 가장 높은 상자와 겹치는 상자들을 제거하는 과정
- 최댓값을 갖지 않는 상자들을 제거
- 과정
1. 확률 기준으로 모든 상자를 정렬하고 먼저 가장 확률이 높은 상자를 취함
2. 각 상자에 대해 다른 모든 상자와의 IOU를 계산
3. 특정 임곗값을 넘는 상자는 제거
1.2 모델 성능 평가
1) 정밀도(Precision)와 재현율(Recall)
- 일반적으로 객체 탐지 모델 평가에 사용되지는 않지만, 다른 지표를 계산하는 기본 지표 역할을 함
- True Positives(`TP`): 예측이 동일 클래스의 실제 상자와 일치하는지 측정
- False Positives(`FP`): 예측이 실제 상자와 일치하지 않는지 측정
- False Negatives(`FN`): 실제 분류값이 그와 일치하는 예측을 갖지 못하는지 측정

- Precision : 찾았다고 주장한 경우에 대한 정확도
- 모델이 안정적이지 않은 특징을 기반으로 객체 존재를 예측하면 거짓긍정(FP)이 많아져서 정밀도가 낮아짐
- 존재한다고 또는 찾았다고 긍정적(Positive)으로 판단한 결과가 얼마나 정확한가 측정
- 어떤 Object가 존재한다고 답한경우에 대해 맞춘 경우의 비율 ( 존재한다고 한 주장에 대한 신뢰도 측정의 의미)
- Recall : 존재하는 Object중에 총 몇 퍼센트나 찾았는지에 대한 비률
- 모델이 너무 엄격해서 정확한 조건을 만족할 때만 객체가 탐지된 것으로 간주하면 거짓부정(FN)이 많아져서 재현율이 낮아짐
- 실제로는 존재하는데 못 찾는 경우가 얼마나 되는지 확인하는 의미
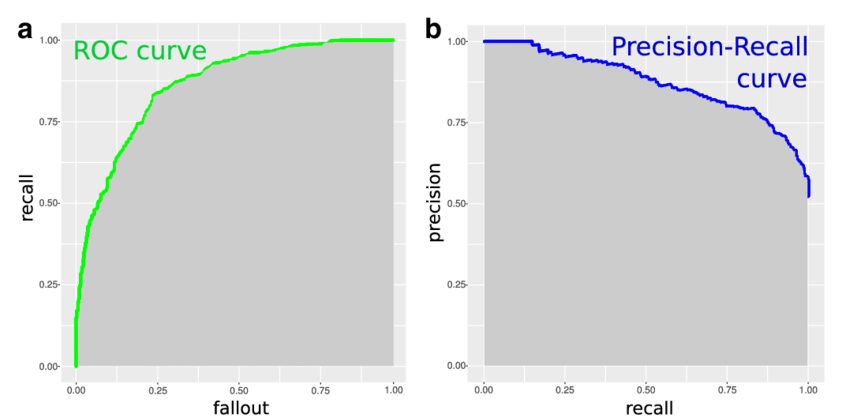
2) 정밀도-재현율 곡선(Precision-Recall Curve)
- 신뢰도 임계값마다 모델의 정밀도와 재현율을 시각화
- 모든 bounding box와 함께 모델이 예측의 정확성을 얼마나 확실하는지 0 ~ 1사이의 숫자로 나타내는 신뢰도를 출력
- 임계값 T에 따라 정밀도와 재현율이 달라짐
- 임계값 T 이하의 예측은 제거함
- T가 1에 가까우면 정밀도는 높지만 재현율은 낮음
- 놓치는 객체가 많아져서 재현율이 낮아짐. 즉, 신뢰도가 높은 예측만 유지하기때문에 정밀도는 높아짐
- T가 0에 가까우면 정밀도는 낮지만 재현율은 높음
- 대부분의 예측을 유지하기때문에 재현율은 높아지고, 거짓긍정(FP)이 많아져서 정밀도가 낮아짐
- 예를 들어, 모델이 보행자를 탐지하고 있으면 특별한 이유없이 차를 세우더라도 어떤 보행자도 놓치지 않도록 재현율을 높여야 함
- 모델이 투자 기회를 탐지하고 있다면 일부 기회를 놓치게 되더라도 잘못된 기회에 돈을 거는 일을 피하기 위해 정밀도를 높여야 함
3) AP (Average Precision, 평균 정밀도) 와 mAP(mean Average Precision)
- 곡선의 아래 영역에 해당
- 항상 1x1 정사각형으로 구성되어 있음
즉, 항상 0 ~ 1 사이의 값을 가짐
- 단일 클래스에 대한 모델 성능 정보를 제공
- 전역 점수를 얻기위해서 mAP를 사용
- 예를 들어, 데이터셋이 10개의 클래스로 구성된다면 각 클래스에 대한 AP를 계산하고, 그 숫자들의 평균을 다시 구함
- mAP 사용 : Object Detection의 성능 평가 지표
- 2개의 Hyper Parameter 사용
- Confidence Threshold : 탐지한 객체 인식에 대한 신뢰도로 보통 0.5 사용
- IOU Threshold : Precision과 Recall로부터 계산. Confidence 를 1.0 에서 0으로 조금씩 줄이면서 Recall값을 0에서 1사이에서 0.1 간격으로 11개 레벨값에 대한 Precision 값을 구해 각 Recall 레벨값에 대한 Precision 값들의 평균값 구
- 최소 2개 이상의 객체를 탐지하는 대회인 PASCAL Visual Object Classes와 Common Objects in Context(COCO)에서 mAP가 사용됨
- COCO 데이터셋이 더 많은 클래스를 포함하고 있기 때문에 보통 Pascal VOC보다 점수가 더 낮게 나옴
1.3 데이터셋 (Dataset)
1) VOC Dataset
- PASCAL VOC (시각적 객체 클래스) 데이터 세트는 잘 알려진 객체 감지, 분할 및 분류 데이터 세트
- 2005년에서 2012년까지 진행되었던 PASCAL VOC challenge에서 쓰이던 데이터셋
- Object Detection 기술의 benchmark로 간주
- 데이터셋에는 20개의 클래스가 존재
background
aeroplane
bicycle
bird
boat
bottle
bus
car
cat
chair
cow
diningtable
dog
horse
motorbike
person
pottedplant
sheep
sofa
train
tvmonitor
- 훈련 및 검증 데이터 : 11,530개
- 이미지 개수:
- object detection: 총 9,963개의 주석이 달린(annotated) 이미지가 포함. 이 중에서 5,011개가 학습 데이터
- segmentation: 422개의 학습 데이터
- ROI에 대한 27,450개의 Annotation이 존재
- 이미지당 2.4개의 객체 존재

2) COCO Dataset
- Common Objects in Context
- 200,000개의 이미지
- 학습(training) 데이터셋: 118,000장의 이미지
- 검증(validation) 데이터셋: 5,000장의 이미지
- 테스트(test) 데이터셋: 41,000장의 이미지
- COCO 데이터셋의 장점
- 다양한 크기의 물체가 존재
- 높은 비율로 작은 물체들이 존재
- Object들이 혼잡하게 존재하고, occlusion(폐색)이 많이 존재
- 덜 iconic 합니다. 여기서 iconic의 의미는 이미지가 특정 카테고리에 명확하게 속해있는 경우를 말합니다. 예를 들어 아래 이미지의 (a)의 이미지들은 누가봐도 명확하게 개, 소 등의 명확하게 특정 카테고리에 속한걸 누구나 알 수 있습니다. (b)의 이미지들은 (a) 보다는 모호하지만, 특정 카테고리에 속하다고 말할 수 있습니다. 그런데 (c)의 경우 어떤 카테고리에 속하는지 분류하기가 모호합니다. 현실세계 사진에서는 (a)나 (b)보단 (c)에 속하는 경우가 훨씬 많이 존재합니다.
- 80개의 카테고리에 500,000개 이상의 객체 Annotation이 존재
person
bicycle
car
motorbike
aeroplane
bus
train
truck
boat
traffic light
fire hydrant
stop sign
parking meter
bench
bird
cat
dog
horse
sheep
cow
elephant
bear
zebra
giraffe
backpack
umbrella
handbag
tie
suitcase
frisbee
skis
snowboard
sports ball
kite
baseball bat
baseball glove
skateboard
surfboard
tennis racket
bottle
wine glass
cup
fork
knife
spoon
bowl
banana
apple
sandwich
orange
broccoli
carrot
hot dog
pizza
donut
cake
chair
sofa
pottedplant
bed
diningtable
toilet
tvmonitor
laptop
mouse
remote
keyboard
cell phone
microwave
oven
toaster
sink
refrigerator
book
clock
vase
scissors
teddy bear
hair drier
toothbrush
- https://cocodataset.org/

2. 객체 탐지의 역사
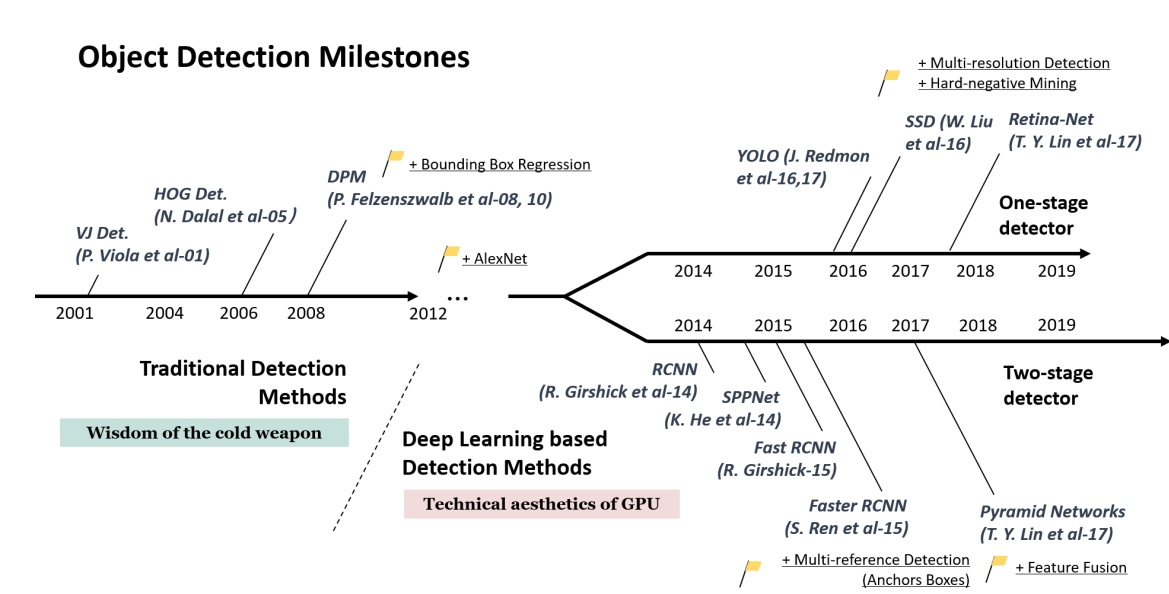
* RCNN (2013)
- Rich feature hierarchies for accurate object detection and semantic segmentation (https://arxiv.org/abs/1311.2524)
- 물체 검출에 사용된 기존 방식인 sliding window는 background를 검출하는 소요되는 시간이 많았는데, 이를 개선시킨 기법으로 Region Proposal 방식 제안
- 매우 높은 Detection이 가능하지만, 복잡한 아키텍처 및 학습 프로세스로 인해 Detection 시간이 매우 오래 걸림
* SPP Net (2014)
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition (https://arxiv.org/abs/1406.4729)
- RCNN의 문제를 Selective search로 해결하려 했지만, bounding box의 크기가 제각각인 문제가 있어서 FC Input에 고정된 사이즈로 제공하기 위한 방법 제안
- SPP은 RCNN에서 conv layer와 fc layer사이에 위치하여 서로 다른 feature map에 투영된 이미지를 고정된 값으로 풀링
- SPP를 이용해 RCNN에 비해 실행시간을 매우 단축시킴
* Fast RCNN (2015)
- Fast R-CNN (https://arxiv.org/abs/1504.08083)
- SPP layer를 ROI pooling으로 바꿔서 7x7 layer 1개로 해결
- SVM을 softmax로 대체하여 Classification 과 Regression Loss를 함께 반영한 Multi task Loss 사용
- ROI Pooling을 이용해 SPP보다 간단하고, RCNN에 비해 수행시간을 많이 줄임
* Fater RCNN(2015)
- Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks (https://arxiv.org/abs/1506.01497)
- RPN(Region proposal network) + Fast RCNN 방식
- Selective Search를 대체하기 위한 Region Proposal Network구현
- RPN도 학습시켜서 전체를 end-to-end로 학습 가능 (GPU사용 가능)
- Region Proposal를 위해 Object가 있는지 없는지의 후보 Box인 Anchor Box 개념 사용
- Anchor Box를 도입해 FastRCNN에 비해 정확도를 높이고 속도를 향상시킴
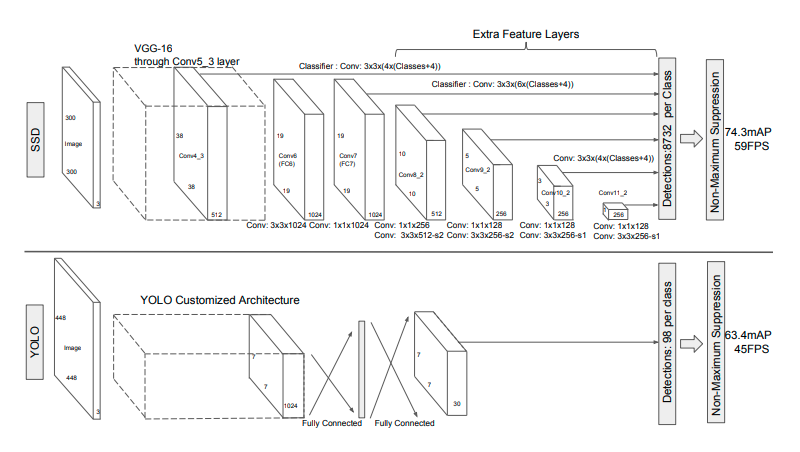
* SSD (2015)
- SSD: Single Shot MultiBox Detector (https://arxiv.org/abs/1512.02325)
- Faster-RCNN은 region proposal과 anchor box를 이용한 검출의 2단계를 걸치는 과정에서 시간이 필요해 real-time(20~30 fps)으로는 어려움
- SSD는 Feature map의 size를 조정하고, 동시에 앵커박스를 같이 적용함으로써 1 shot으로 물체 검출이 가능
- real-time으로 사용할 정도의 성능을 갖춤 (30~40 fps)
- 작은 이미지의 경우에 잘 인식하지 못하는 경우가 생겨서 data augmentation을 통해 mAP를 63에서 74로 비약적으로 높임
* RetinaNet (2017)
- Focal Loss for Dense Object Detection (https://arxiv.org/abs/1708.02002)
- RetinaNet이전에는 1-shot detection과 2-shot detection의 차이가 극명하게 나뉘어 속도를 선택하면 정확도를 trade-off 할 수 밖에 없는 상황
- RetinaNet은 Focal Loss라는 개념의 도입과 FPN 덕분에 기존 모델들보다 정확도도 높고 속도도 여타 1-shot detector와 비견되는 모델
- Detection에선 검출하고 싶은 물체와 (foreground object) 검출할 필요가 없는 배경 물체들이 있는데 (background object) 배경 물체의 숫자가 매우 많을 경우 배경 Loss를 적게 하더라도 숫자에 압도되어 배경의 Loss의 총합을 학습해버림 (예를 들어, 숲을 배경으로 하는 사람을 검출해야하는데 배경의 나무가 100개나 되다보니 사람의 특징이 아닌 나무가 있는 배경을 학습해버림)
- Focal Loss는 이런 문제를 기존의 crossentropy 함수에서 (1-sig)을 제곱하여 background object의 loss를 현저히 줄여버리는 방법으로 loss를 변동시켜 해결
- Focal Loss를 통해 검출하고자 하는 물체와 관련이 없는 background object들은 학습에 영향을 주지 않게 되고, 학습의 다양성이 더 넓어짐 (작은 물체, 큰 물체에 구애받지 않고 검출할 수 있게됨)
- 실제로 RetinaNet은 object proposal을 2000개나 실시하여 이를 확인
* Mask R-CNN (2018)
- Mask R-CNN (https://arxiv.org/pdf/1703.06870.pdf)
* YOLO (2018)
- YOLOv3: An Incremental Improvement (https://arxiv.org/abs/1804.02767)
- YOLO는 v1, v2, v3의 순서로 발전하였는데, v1은 정확도가 너무 낮은 문제가 있었고 이 문제는 v2까지 이어짐
- 엔지니어링적으로 보완한 v3는 v2보다 살짝 속도는 떨어지더라도 정확도를 대폭 높인 모델
- RetinaNet과 마찬가지로 FPN을 도입해 정확도를 높임
- RetinaNet에 비하면 정확도는 4mAP정도 떨어지지만, 속도는 더 빠르다는 장점
* RefineDet (2018)
- Single-Shot Refinement Neural Network for Object Detection (https://arxiv.org/pdf/1711.06897.pdf)
* M2Det (2019)
- M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network (https://arxiv.org/pdf/1811.04533.pdf)
* EfficientDet (2019)
- EfficientDet: Scalable and Efficient Object Detection (https://arxiv.org/pdf/1911.09070v1.pdf)
* YOLOv4 (2020)
- YOLOv4: Optimal Speed and Accuracy of Object Detection (https://arxiv.org/pdf/2004.10934v1.pdf)
- YOLOv3에 비해 AP, FPS가 각각 10%, 12% 증가
- YOLOv3와 다른 개발자인 AlexeyBochkousky가 발표
- v3에서 다양한 딥러닝 기법(WRC, CSP ...) 등을 사용해 성능을 향상시킴
- CSPNet 기반의 backbone(CSPDarkNet53)을 설계하여 사용
* YOLOv5 (2020)
- YOLOv4에 비해 낮은 용량과 빠른 속도 (성능은 비슷)
- YOLOv4와 같은 CSPNet 기반의 backbone을 설계하여 사용
- YOLOv3를 PyTorch로 implementation한 GlennJocher가 발표
- Darknet이 아닌 PyTorch 구현이기 때문에, 이전 버전들과 다르다고 할 수 있음
* 이후
- 수 많은 YOLO 버전들이 탄생
- Object Detection 분야의 논문들이 계속해서 나오고 있음
3. 객체 탐지 아키텍처
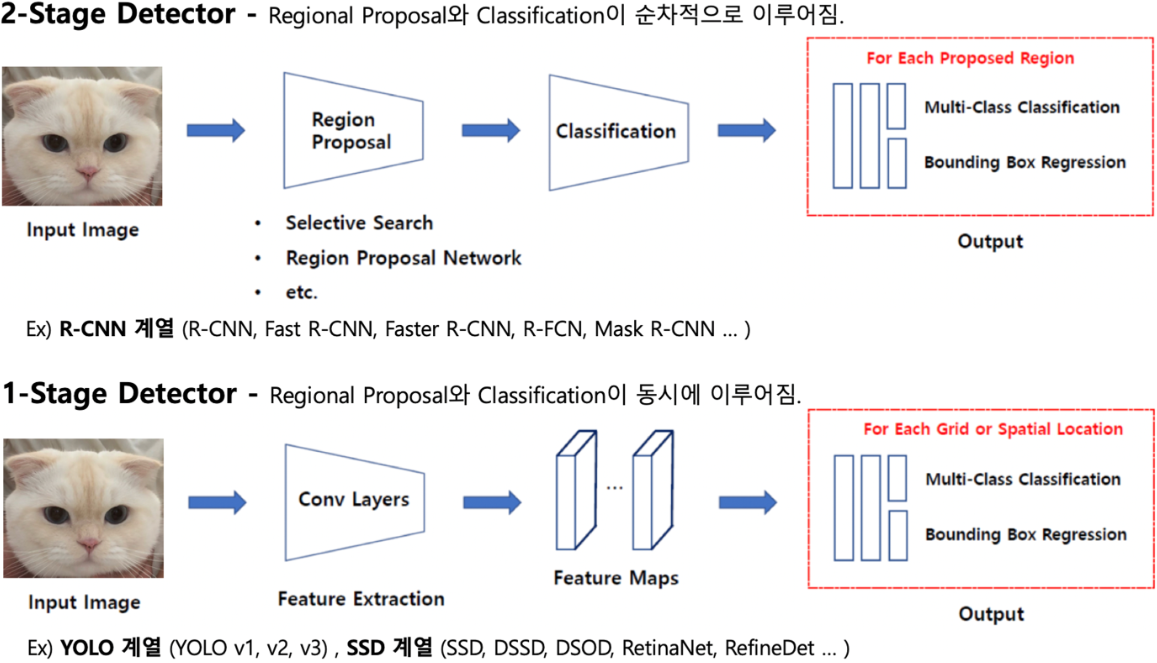
- Two Stage Detector: object가 있을 법한 위치의 후보(proposals)들을 뽑아내는 단계, 이후 실제로 object가 있는지를 Classification과 정확한 바운딩 박스를 구하는 Regression을 수행하는 단계가 분리되어 있음. 예:Faster-RCNN
- One Stage Detector:객체의 검출과 분류, 그리고 바운딩박스 regression을 한 번에 하는 방법
< 전통적인 객체 탐지 기법 - 영역 제안(Region Proposal) 기법 >
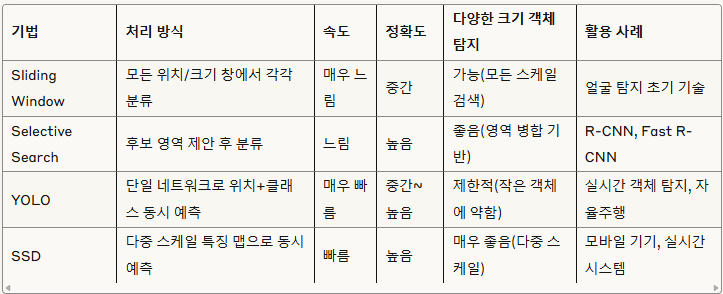
- Sliding Window 기법

- 이미지를 다양한 크기의 창(window)으로 스캔하면서 각 위치에서 객체가 있는지 분류하는 방식 (검출하고자 하는 입력 이미지에 정해진 크기의 Bounding Box를 만들어 방향을 이동하면서 물체가 있을 법한 box나 영역을 추출하는 것)
- 모든 영역을 탐색해야 하기 때문에 시간이 많이 소요되어 비효율적이라는 특성이 있습니다.
- 이미지를 가로 질러 고정 된 크기의 window를 여러 배율로 슬라이드하는 것을 볼 수 있음.
- 이러한 각 단계에서 window가 중지되고 일부 feature를 계산한 다음 영역을 아래와 같이 분류
- 이 영역에 얼굴이 포함되어 있습니다 à Yes
- 이 영역에 얼굴이 포함되어 있지 않습니다 à No
[작동 방식]
1. 창 생성: 다양한 크기와 비율(예: 64×64, 128×128 등)의 탐색 창을 준비합니다.
2. 슬라이딩 과정: 각 창을 일정 스텝(보통 4~8픽셀)씩 이동하며 이미지 전체를 스캔합니다.
3. 특징 추출: 각 창에서 HOG(Histogram of Oriented Gradients), SIFT 등의 특징을 추출합니다.
4. 분류: SVM(Support Vector Machine)이나 AdaBoost 같은 분류기로 각 창에 객체가 있는지 판단합니다.
5. 후처리: NMS(Non-Maximum Suppression)를 적용해 중복 검출을 제거합니다.
=> 계산 복잡도: 이미지 크기 × 창 크기 종류 × 스케일 수 → 수만~수십만 번의 분류 연산
- Selective Search (SS) 기법

- 이미지의 특성(색상, 질감, 크기 등)을 고려해 객체가 있을 법한 영역(Region Proposal)을 먼저 제안하고, 그 영역들만 분류하는 방식입니다.
- Selective Search(SS)는 색상, 질감 및 모양과 같은 다양한 하위 수준 이미지 기능을 결합하여 이미지 영역의 계층적 그룹을 만드는
방식으로 작동
[작동방식]
1. 초기 분할: 이미지를 작은 초기 영역들로 과분할합니다(약 2,000개 정도).
2. 유사도 계산: 인접 영역 간 색상, 질감, 크기, 형태 유사도를 계산합니다.
3. 영역 병합: 유사도가 가장 높은 영역들부터 점진적으로 병합합니다.
4. 후보 영역 생성: 병합 과정에서 생성된 모든 영역들을 객체 후보(약 2,000개)로 간주합니다.
5. 분류: 각 후보 영역에서 특징을 추출하고 분류기를 적용해 객체 여부를 판단합니다.
4. YOLO (You Only Look Once)
- https://www.ultralytics.com/ko/yolo : 테스트해보기
- https://velog.io/@choonsik_mom/Object-Detection-with-yolo-NAS-zpetis4o 성능비
- 2015년 Joseph Redmon 이 아키텍처를 논문과 함께 발표함, 가장 빠른 객체 검출 알고리즘 중 하나
- Yolo 형식 : 클래스 번호|x의 center좌표|y의 center좌표|너비|높이
- 256x256 사이즈의 이미지
- Yolov4까지는 파이썬, 텐서플로 기반 프레임워크가 아닌 C++로 구현된 코드 기준 GPU 사용 시, 초당 170 프레임(170 FPS, frames per second), Yolov5부터는 PyTorch로 개발이 이루어져 2023년 현재 빠른속도, 사용자 친화적인 파이썬 인터페이스를 제공하는 Yolov8 (SOFA) 아키텍처로 진화
- 작은 크기의 물체를 탐지하는데는 어려움
[작동 방식]
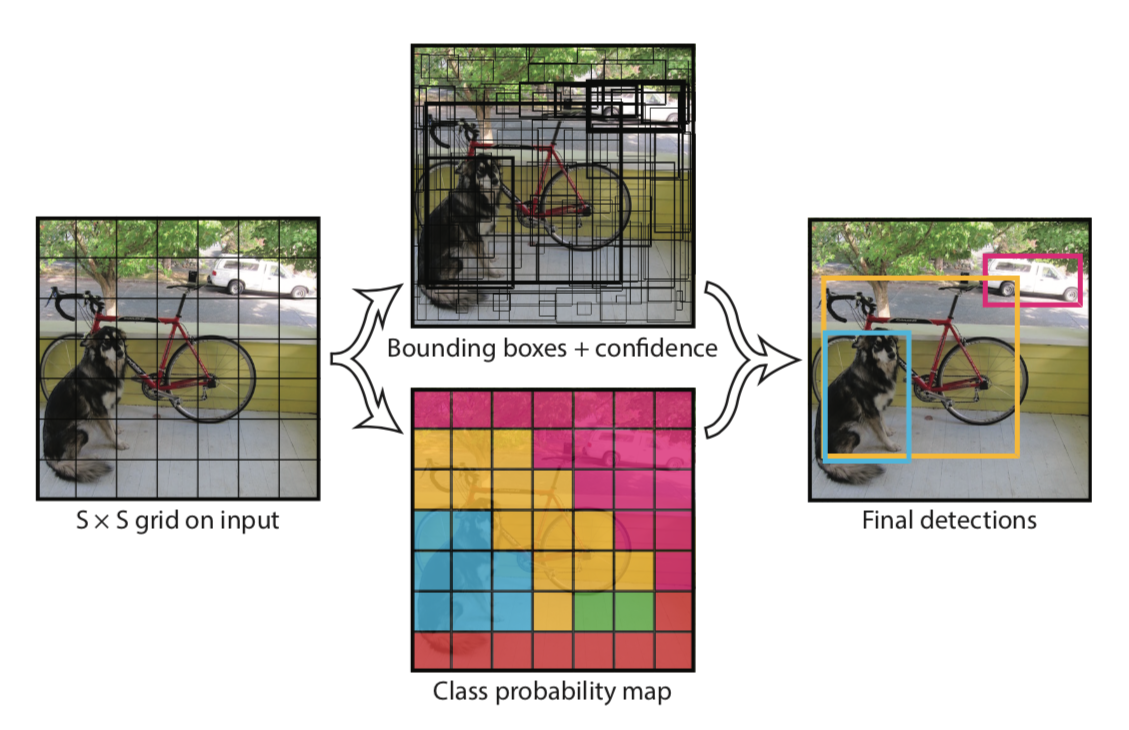
1. 그리드 분할: 이미지를 S×S 그리드(일반적으로 7×7 또는 13×13)로 분할합니다.
2. 네트워크 구조: 단일 CNN(Convolutional Neural Network)을 통과시켜 전체 이미지의 특징을 추출합니다.
3. 예측 값:
- 각 그리드 셀마다 B개의 바운딩 박스를 예측
- 바운딩 박스는 5개 값(x, y, w, h, confidence) 포함
- 각 그리드 셀에서 C개 클래스의 조건부 확률 예측
4. 출력 형태: S×S×(5B+C) 텐서
- 예: 7×7 그리드, 2개 바운딩 박스, 20개 클래스 → 7×7×30 텐서
5. 후처리: 낮은 신뢰도의 박스 제거 및 NMS 적용
= > 특징: 전체 이미지를 한 번에 처리하므로 매우 빠르며(초당 45~155프레임), 객체의 전체적인 컨텍스트를 고려할 수 있습니다.
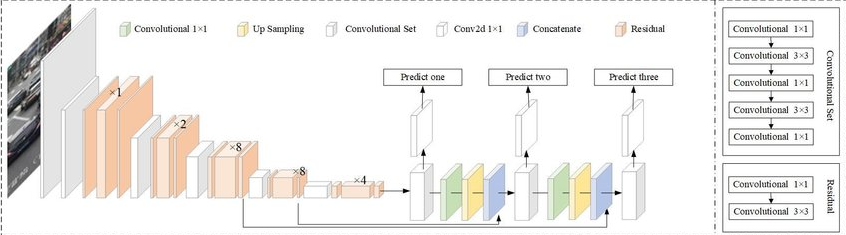
4.1 YOLO 아키텍처
- 백본 모델(backbone model) 기반
- 특징 추출기(Feature Extractor)라고도 불림
- YOLO는 자체 맞춤 아키텍처 사용
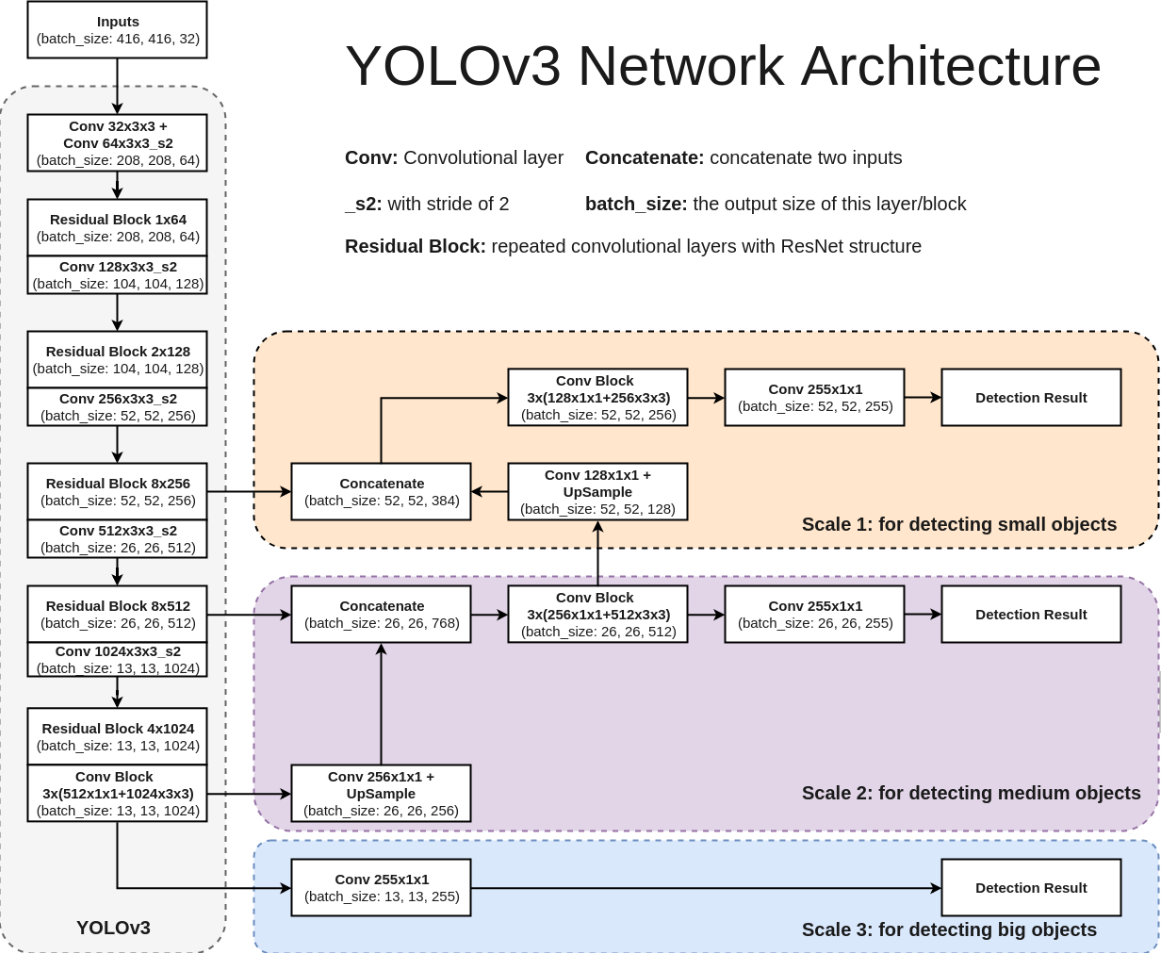
- 어떤 특징 추출기 아키텍처를 사용했는지에 따라 성능 달라짐
- 마지막 계층은 크기가 w x h x D인 특징 볼륨 출력
- w x h는 그리드의 크기이고 D는 특징 볼륨 깊이
4.2 YOLO 계층 출력
- 마지막 계층 출력은 w x h x M 행렬
- M = B x (C + 5)
- B : 그리드 셀당 경계 상자 개수
- C : 클래스 개수
- 클래스 개수에 5를 더한 이유는 해당 값 만큼의 숫자를 예측해야함
- tx, ty는 경계상자의 중심 좌표를 계산
- tw, th는 경계상자의 너비와 높이를 계산
- c는 객체가 경계 상자 안에 있다고 확신하는 신뢰도
- p1, p2, ..., pC는 경계상자가 클래스 1, 2, ..., C의 객체를 포함할 확률
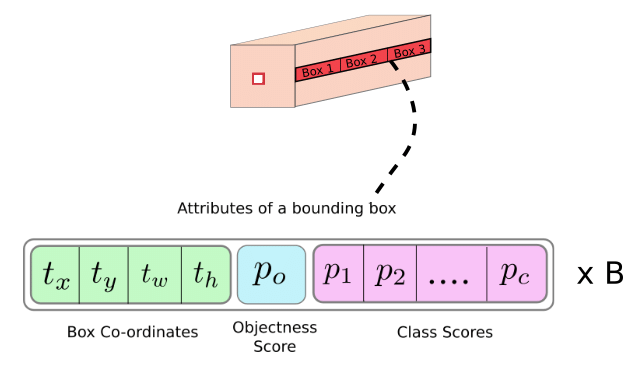
- Objectness Score : 바운딩 박스에 객체가 포함되어 있을 확률
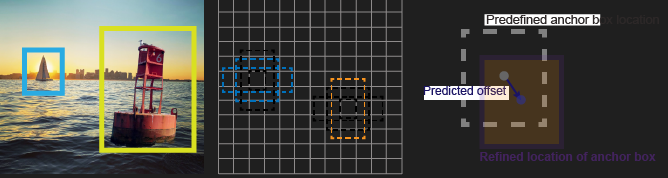
4.2 앵커 박스 (Anchor Box)
- YOLOv2에서 도입
- 사전 정의된 상자(prior box)
- 객체에 가장 근접한 앵커 박스를 맞추고 신경망을 사용해 앵커 박스의 크기를 조정하는 과정 때문에 tx, ty, tw, th이 필요
4.4 YOLOv8
* https://github.com/ultralytics/
* https://www.ultralytics.com
1.Yolov8 이란?
- YOLOv8은 객체 탐지(Object Detection), 이미지 분류(Image Classification), 인스턴스 분할(Instance Segmentation) 작업에 사용할 수 있는 최신 기술의 YOLO 모델입니다. YOLOv8은 영향력 있는 YOLOv5 모델을 개발한 [Ultralytics](https://ultralytics.com/?ref=blog.roboflow.com)에 의해 개발되었습니다. YOLOv8은 YOLOv5와 비교하여 수많은 구조적 및 개발자 경험의 변화와 개선 사항을 포함하고 있습니다.
- YOLOv8은 이 글을 쓰는 시점에서 Ultralytics가 새로운 기능을 개발하고 커뮤니티로부터의 피드백에 응답하면서 활발한 개발이 진행되고 있습니다. 실제로 Ultralytics가 모델을 출시하면 장기적인 지원을 받게 됩니다. 이 기관은 커뮤니티와 협력하여 모델을 최상의 상태로 만들기 위해 노력합니다.
- 강력한 기초 모델과 함께 YOLOv5 관리자들은 모델을 둘러싼 건강한 소프트웨어 생태계를 지원하는 데 전념했습니다. 그들은 적극적으로 문제를 해결하고 커뮤니티의 요구에 따라 레포의 기능을 향상시켰습니다.
- 지난 두 해 동안, YOLOv5 PyTorch 레포에서 다양한 모델들이 파생되었으며, [Scaled-YOLOv4](https://roboflow.com/model/scaled-yolov4?ref=blog.roboflow.com), [YOLOR](https://blog.roboflow.com/train-yolor-on-a-custom-dataset/), [YOLOv7](https://blog.roboflow.com/yolov7-breakdown/) 등이 포함됩니다. [YOLOX](https://blog.roboflow.com/how-to-train-yolox-on-a-custom-dataset/) 및 [YOLOv6](https://blog.roboflow.com/how-to-train-yolov6-on-a-custom-dataset/)와 같은 다른 모델들은 각자의 PyTorch 기반 구현에서 세계적으로 등장했습니다. 이 과정에서 각 YOLO 모델은 모델의 정확도와 효율성을 향상시키는 새로운 SOTA 기술을 가져왔습니다.
- 최근 6개월 동안, Ultralytics는 최신 SOTA 버전인 YOLOv8을 연구하는 데 집중했습니다. YOLOv8은 2023년 1월 10일에 출시되었습니다. 이 모델은 이전 YOLO 버전들의 효율성과 정확도를 향상시킨 새로운 기술을 결합하여 더욱 강력한 객체 탐지 및 인스턴스 분할 성능을 제공합니다. 또한, YOLOv8은 사용자 친화적인 API와 확장성 있는 구조를 제공하여 더 많은 개발자들이 이 모델을 쉽게 적용하고 수정할 수 있게 되었습니다.
- YOLOv8은 계속해서 발전하고 있으며, Ultralytics 및 커뮤니티는 이 모델을 개선하기 위해 지속적으로 협력하고 있습니다. 이렇게 함으로써 YOLO 시리즈는 앞으로도 컴퓨터 비전 분야에서 지속적으로 중요한 역할을 하게 될 것입니다.
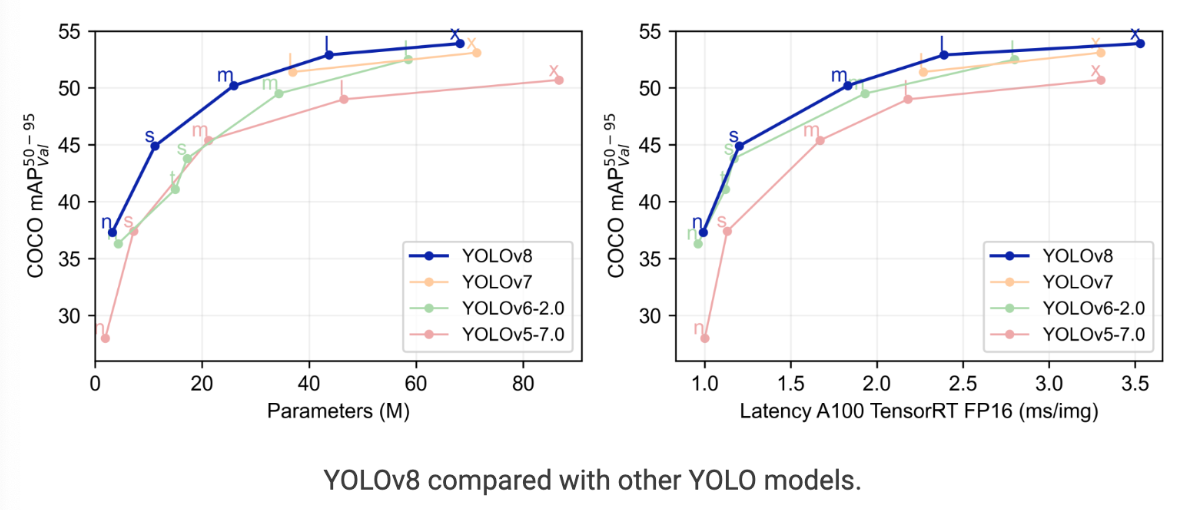
YOLOv8 vs YOLOv7 vs YOLOv6 vs YOLOv5
- 당장 YOLOv8 모델은 이전 YOLO 모델에 비해 훨씬 더 나은 성능을 보이는 것 같습니다. YOLOv5 모델뿐만 아니라 YOLOv8 모델도 YOLOv7 및 YOLOv6 모델에 비해 앞서고 있습니다.
5. SSD (Single Shot MultiBox Detector)
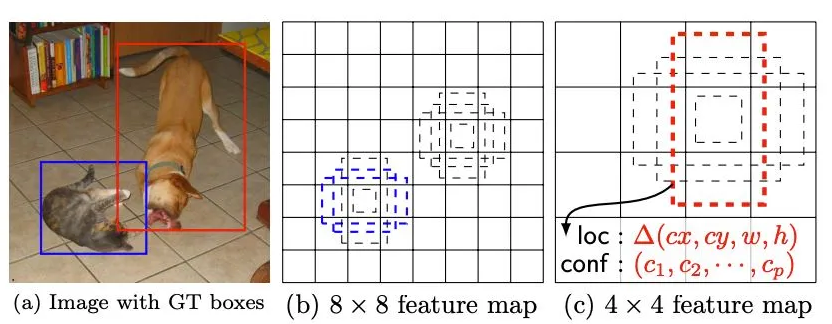
- SSD는 "Single Shot MultiBox Detector"의 약자로, 객체 탐지를 위한 딥러닝 알고리즘입니다. "Single Shot"은 객체 위치와 클래스를 단일 네트워크 통과로 예측한다는 의미이고, "MultiBox"는 다양한 크기와 비율의 기본 박스를 사용한다는 의미입니다.
1. 기본 네트워크: VGG16이나 ResNet과 같은 사전 학습된 네트워크를 기반으로 합니다.
2. 다중 스케일 특징 맵: 기본 네트워크의 여러 층에서 특징 맵을 추출합니다.
- 38×38, 19×19, 10×10, 5×5, 3×3, 1×1 등 다양한 해상도
3. 기본 박스(Default Box):
- 각 특징 맵의 각 위치마다 여러 개의 기본 박스 설정
- 다양한 크기와 비율(aspect ratio) 사용
- 총 약 8,000개의 기본 박스 생성
4. 예측 값:
- 각 기본 박스마다 위치 오프셋(cx, cy, w, h) 예측
- 각 기본 박스마다 C+1개 클래스(배경 포함) 신뢰도 예측
5. 후처리: 임계값 이하 박스 제거 및 NMS 적용
= > 특징: 다양한 스케일의 특징 맵을 사용하므로 다양한 크기의 객체를 효과적으로 탐지할 수 있으며, YOLO와 마찬가지로 단일 네트워크로 실시간 처리가 가능합니다.
<4가지 방법의 주요 차이점 비교>
Object Detection - Yolov8 [사전학습된 모델 사용하여 예측]
- Yolo는 워싱턴대의 Joseph Redmon등이 주축이 되서 만든 알고리즘으로 Darknet이라는 C 기반의 딥러닝 프레임에서 만듬 (Darknet은 Tensorflow와 같은 딥러닝 프레임웍)
- 이후 Joseph Redmon 이 더이상 computer vision연구를 하지 않겠다고 선언한뒤 Yolo의 후속 버전은 계속 다른 사람들이 연구하게 됨
- Yolo v4는 이후 Alexey Bochkoviskiy가 구현했는데, 얼마되지 않아서 glenn jocher가 Ultralytics 라는 개인 스타트업을 만들고 다시 Yolo v5를 내놓음
< 진행 절차 >
1. MS COCO Dataset으로 사전학습된 Yolov8 모델 Prediction 기능이용 시 예측에 사용할 이미지 준비
2. Colab 으로 데이터셋 업로드
3. ultralytics 패키지 설치하기
- https://www.ultralytics.com/ko
- https://github.com/ultralytics
```python
pip install ultralytics
```
4. 모델 사용하기
```python
from ultralytics import YOLO
model = YOLO('yolov8n.pt')
```
5. 예측하기
```python
results = model.predict('test_image.jpg')
# Process results list
for result in results:
boxes = result.boxes # Boxes object for bounding box outputs
masks = result.masks # Masks object for segmentation masks outputs
keypoints = result.keypoints # Keypoints object for pose outputs
probs = result.probs # Probs object for classification outputs
obb = result.obb # Oriented boxes object for OBB outputs
result.show() # display to screen
result.save(filename="result.jpg") # save to disk
'(Telechips) AI 시스템 반도체 SW 개발자 교육 > 비전과AI머신러닝' 카테고리의 다른 글
| Mini Project1 - No Smoking Area Project (with YOLOv8) (0) | 2025.05.13 |
|---|---|
| 16일차 (0) | 2025.05.12 |
| 14일차 (0) | 2025.05.08 |
| 13일차 (0) | 2025.05.07 |
| 12일차 (0) | 2025.04.29 |


