
- 분류 전체보기 (427)

- C (66)
- C++ (45)
- Python (28)
- OpenCV (12)
- Arduino (21)
- Raspberry Pi (11)
- TCP IP 소켓 프로그래밍 (13)
- SQL (6)
- 대학교 2학년 1학기 (12)
- 대학교 2학년 2학기 (0)
- 대학교 3학년 1학기 (8)
- 대학교 3학년 2학기 (0)
- 대학교 4학년 1학기 (16)
- (두산로보틱스) ROKEY 부트 캠프 (113)
- (Telechips) AI 시스템 반도체 SW 개.. (75)
- C (9)
- C언어 ROS 문제 (1)
- C언어, Python, C++ 과제 문제 (0)
- ATmega128A 마이크로컨트롤러 프로그래밍 (12)
- ATmega128A mini Project (2)
- STM32CubeIDE (11)
- STM32CubeIDE mini Project (2)
- 비전과AI머신러닝 (17)
- MySQL & Visual Studio C 연동 .. (1)
- MFC Application (1)
- 비전과AI머신러닝 mini Project (1)
- SoC 시스템 반도체를 위한 온디바이스 AI (11)
- SoC 시스템 반도체를 위한 임베디드 리눅스 (7)
- OPIC 공부 (1)
printf("ho_tari\n");
13일차 본문
2025.05.07
차선감지
1. JdOpencvLaneDetect 클래스
- curr_steering_angle
- 프레임 간 “이전 조향각”을 저장합니다. 기본값은 90° (직진).
- get_lane(frame)
- 원본 프레임을 윈도우에 띄우고 (show_image)
- detect_lane로부터 검출된 차선 좌표(lane_lines)와 차선만 그린 이미지(frame)를 반환
- get_steering_angle
- 차선을 못 찾으면 (0, None) 반환
- compute_steering_angle → new_angle 계산
- stabilize_steering_angle로 급격한 변화 제한 → curr_steering_angle 업데이트
- 최종 조향각 시각화 (display_heading_line)
2. 프레임 처리 파이프라인
2.1 엣지 검출: detect_edges(frame)
- BGR → HSV 변환
- HSV 공간에서 ‘색상(H)’ 필터링이 쉽기 때문
- 두 구간의 적색 마스크
- [0–40] 구간 + [160–180] 구간을 합쳐 빨간색 계열 포괄
- S, V 채널은 [50–255]로 충분히 밝고 선명한 빨간색만 잡음
- Canny 엣지 검출
- 1차 threshold = 200, 2차 = 400
- 작은 노이즈는 무시하고, 강한 경계선만 검출
2.2 관심 영역 마스킹 : region_of_interest(canny)
- 왜 하단 절반?
- 카메라가 앞쪽 도로만 보도록, 하늘·차량 전면부는 제외
- fillPoly + bitwise_and
- 마스크 영역만 살리고 나머지는 0(검정) 처리
2.3 허프 선분 검출 : detect_line_segments(cropped_edges)
- rho, angle: 그리드 정밀도(1px, 1°)
- min_votes: 직선으로 간주하려면 최소 10개의 뷰(교차점) 필요
- minLineLength/maxLineGap
- 짧은 선분을 버리고, Gap 4px 이하 이으면 연결
2.4 선분 평균화 : average_slope_intercept(frame, line_segments)
1. 기울기·절편 계산
fit = np.polyfit((x1, x2), (y1, y2), 1)
slope, intercept = fit2. 좌/우 차선 분류
- slope<0 & 화면 왼쪽 2/3에 있을 때 → 좌측 후보
- slope>0 & 화면 오른쪽 1/3에 있을 때 → 우측 후보
- |slope|>0.75 로 너무 완만한 선분 버림
3. 평균화 & 좌표 변환
avg = np.average(fits, axis=0) # [slope, intercept]
[[x1, y1, x2, y2]] = make_points(frame, avg)
- make_points는 y1=바닥, y2=중간 높이로 고정한 뒤
- x = (y − intercept) / slope 로 계산, 프레임 밖 좌표는 클램핑
2.5 조향 각도 계산 : compute_steering_angle
- 단일 차선: 선분 끝점(x2) 기준으로 얼마나 벗어났는지
- 이중 차선: 좌·우 차선 끝점 평균과 화면 중앙(mid) 차이
- +90: 90°가 “직진” 기준, <90°는 좌회전, >90°는 우회전
2.6 각도 안정화 : stabilize_steering_angle
- 두 차선 모두 검출되면 ±5°까지, 한 차선이면 ±1° 허용
- 급격한 휠 턴 방지
3. 시각화 유틸
- display_lines
- 빈 이미지에 녹색 차선 그린 뒤 원본과 α-blend
- display_heading_line
- 빨간색 화살표 : 화면 하단 중앙 → 화면 중간 높이, steering angle 방향
4. 나머지 헬퍼 함수
- length_of_line_segment: 피타고라스
- show_image(title, frame, show):
- show 플래그가 True일 때만 cv2.imshow
- 주의: cv2.waitKey(1)가 밖에서 반드시 호출되어야 창이 갱신됩니다.
- make_points:
- (slope, intercept) → (x1,y1),(x2,y2) 좌표 생성
- 프레임 밖 좌표는 [-width, 2*width] 범위로 클램핑
핵심 정리
- 색상 필터 → 엣지 검출 → ROI 마스크 → 허프 변환 →
- 선분 분류·평균화 → 조향각 계산 → 각도 안정화 → 시각화
이 파이프라인 하나하나가 자율주행의 ‘차선 인식 → 차선 유지’ 로직을 구현합니다.
각 함수의 파라미터(HSV 임계치, Canny threshold, Hough 파라미터, 안정화 임계)를 튜닝해 주행 환경(조명, 도로 색상)에 맞춰 조절하면 훨씬 견고한 시스템을 만들 수 있습니다.
# 🚗 자율주행 라인 감지 주요 함수 정리 (OpenCV 중심)
---
## 🧩 1. `detect_edges(frame)`
```python
def detect_edges(frame):
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
lower_red = np.array([0, 70, 50])
upper_red = np.array([10, 255, 255])
mask1 = cv2.inRange(hsv, lower_red, upper_red)
lower_red2 = np.array([170, 70, 50])
upper_red2 = np.array([180, 255, 255])
mask2 = cv2.inRange(hsv, lower_red2, upper_red2)
red_mask = mask1 | mask2
edges = cv2.Canny(red_mask, 200, 400)
return edges
```
- 🎯 **역할**: 빨간색 차선의 에지(윤곽선) 검출
- 🔧 **사용 함수**:
- `cv2.cvtColor`: HSV 색 변환
- `cv2.inRange`: 빨간색 마스크 추출
- `cv2.Canny`: 에지 검출
---
## 🧩 2. `region_of_interest(canny)`
```python
def region_of_interest(canny):
height, width = canny.shape
mask = np.zeros_like(canny)
polygon = np.array([[(0, height), (width, height), (width, height // 2), (0, height // 2)]], np.int32)
cv2.fillPoly(mask, polygon, 255)
cropped_edges = cv2.bitwise_and(canny, mask)
return cropped_edges
```
- 🎯 **역할**: 화면 하단 절반만 관심 영역으로 설정
- 🔧 **사용 함수**:
- `cv2.fillPoly`: 마스크 생성
- `cv2.bitwise_and`: ROI 외 제거
---
## 🧩 3. `detect_line_segments(cropped_edges)`
```python
def detect_line_segments(cropped_edges):
return cv2.HoughLinesP(cropped_edges, 1, np.pi / 180, 10, np.array([]), minLineLength=8, maxLineGap=4)
```
- 🎯 **역할**: 차선으로 추정되는 직선 구간 검출
- 🔧 **사용 함수**:
- `cv2.HoughLinesP`: 확률적 허프 변환
---
## 🧩 4. `average_slope_intercept(frame, line_segments)`
```python
def average_slope_intercept(frame, line_segments):
height, width, _ = frame.shape
left_fit = []
right_fit = []
for segment in line_segments:
x1, y1, x2, y2 = segment[0]
if x1 == x2:
continue
slope = (y2 - y1) / (x2 - x1)
intercept = y1 - slope * x1
if slope < 0:
left_fit.append((slope, intercept))
else:
right_fit.append((slope, intercept))
lane_lines = []
if left_fit:
left_fit_avg = np.average(left_fit, axis=0)
lane_lines.append(make_points(frame, left_fit_avg))
if right_fit:
right_fit_avg = np.average(right_fit, axis=0)
lane_lines.append(make_points(frame, right_fit_avg))
return lane_lines
```
- 🎯 **역할**: 좌/우 차선 평균화 및 대표 선 생성
- 🔧 **관련 함수**: `make_points`
---
## 🧩 5. `make_points(frame, line)`
```python
def make_points(frame, line):
height, width, _ = frame.shape
slope, intercept = line
y1 = height
y2 = int(y1 * 0.5)
x1 = int((y1 - intercept) / slope)
x2 = int((y2 - intercept) / slope)
return [[x1, y1, x2, y2]]
```
- 🎯 **역할**: 평균화된 직선 정보 → 이미지상의 점 좌표 변환
---
## 🧩 6. `display_lines(frame, lines)`
```python
def display_lines(frame, lines, line_color=(0, 255, 0), line_width=6):
line_image = np.zeros_like(frame)
if lines is not None:
for line in lines:
x1, y1, x2, y2 = line[0]
cv2.line(line_image, (x1, y1), (x2, y2), line_color, line_width)
return cv2.addWeighted(frame, 0.8, line_image, 1, 1)
```
- 🎯 **역할**: 검출된 차선을 원본 영상에 시각화
- 🔧 **사용 함수**:
- `cv2.line`: 선 그리기
- `cv2.addWeighted`: 원본과 선 이미지 합성
---
## 🧩 7. `compute_steering_angle(frame, lane_lines)`
```python
def compute_steering_angle(frame, lane_lines):
height, width, _ = frame.shape
if len(lane_lines) == 1:
x1, _, x2, _ = lane_lines[0][0]
x_offset = x2 - x1
elif len(lane_lines) == 2:
_, _, left_x2, _ = lane_lines[0][0]
_, _, right_x2, _ = lane_lines[1][0]
mid = width // 2
x_offset = (left_x2 + right_x2) // 2 - mid
else:
x_offset = 0
y_offset = height // 2
angle_to_mid_radian = math.atan(x_offset / y_offset)
angle_to_mid_deg = int(angle_to_mid_radian * 180.0 / math.pi)
return angle_to_mid_deg + 90
```
- 🎯 **역할**: 현재 차선 기준 조향 각도 계산
---
## 🧩 8. `display_heading_line(frame, steering_angle)`
```python
def display_heading_line(frame, steering_angle, line_color=(0, 0, 255), line_width=5):
heading_image = np.zeros_like(frame)
height, width, _ = frame.shape
steering_angle_radian = steering_angle / 180.0 * math.pi
x1 = width // 2
y1 = height
x2 = int(x1 - height / 2 / math.tan(steering_angle_radian))
y2 = int(height / 2)
cv2.line(heading_image, (x1, y1), (x2, y2), line_color, line_width)
return cv2.addWeighted(frame, 0.8, heading_image, 1, 1)
```
- 🎯 **역할**: 현재 조향 방향을 시각적으로 표현
- 🔧 **사용 함수**: `cv2.line`, `cv2.addWeighted`
---
## 🧩 9. `stabilize_steering_angle(...)`
```python
def stabilize_steering_angle(curr_angle, new_angle, lines_count, max_deviation=5):
max_deviation *= lines_count
angle_diff = new_angle - curr_angle
if abs(angle_diff) > max_deviation:
stabilized_angle = int(curr_angle + max_deviation * angle_diff / abs(angle_diff))
else:
stabilized_angle = new_angle
return stabilized_angle
```
- 🎯 **역할**: 조향각 급변 방지, 안정적인 주행 유지
왜 CNN인가?
- 이미지를 1D 벡터 입력으로 평면화하면 2D 이미지의 공간적 특징이 손실됨

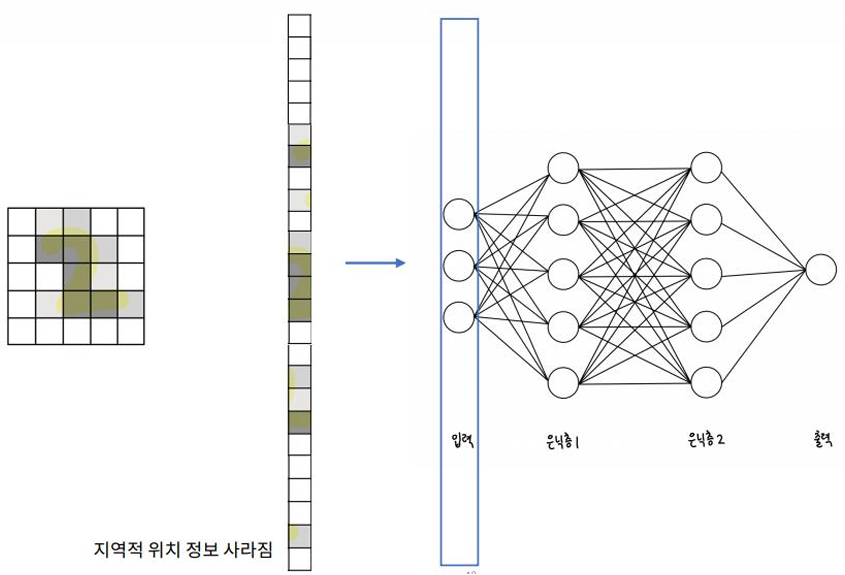
CNN (Convolution Neural Network, 합성곱신경망)
- CNN 구조

CNN 개요
- Input Image : 이미지를 하나의 입력으로 취함
- Convolution Layers : Feature Extraction을 수행하는 Layer
- Convolution Layer + ReLU : Feature 추출, 의미 없는 특징을 zero화
- Pooling Layer : Feature 개수 축소, 중요한 Feature만 유지 (선택적 작업)
- Fully-Connected Layer : 비선형 조합 학습 및 분류 작업 수행하는 Layer
- Output Class : 작업의 결과

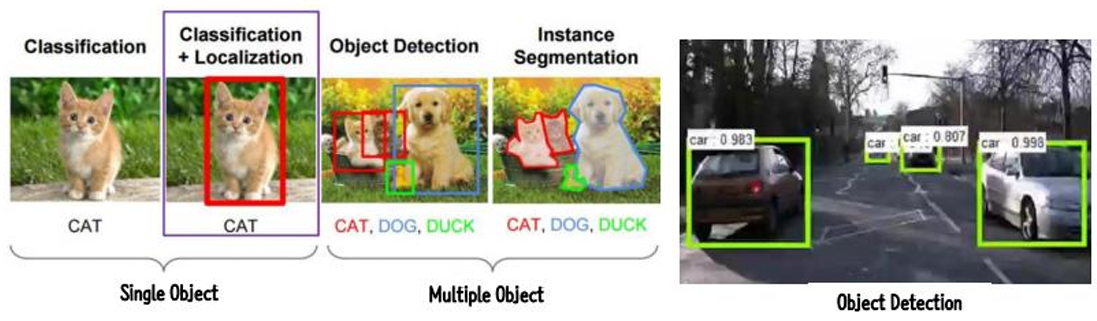
CNN 활용분야
- 분류 (Classification)
- 지역화 (Localization)
- 이미지 세분화 (Image Segmentation)
- 물체 감지 (Object Detection)
CNN 이해 - 필터 커널 (Filter Kernel)
- Filter (Convolution Kernel Matrix)를 적용하여 입력에 대해 특정 성분에 대해서만 뽑아내는 작업
- 예) 사선 정보, 직선 정보, 동그란 정보, 각진 정보, ...
- 알고 싶은 특정 성분에 따라 Filter의 모양이 다름
- CNN은 Filter를 갱신하면서 학습하는 것임
- Image에 특정 Filter를 Convolution한 결과를 Feature Map이라고 함
- Feature Map은 Image에 적용된 Filter 개수 만큼의 Channel을 갖게 됨
- n개의 Filter가 적용된 경우 n개 Channel
- Stride : Filter를 순회하는 간격, Stride가 2로 설정되면 2칸씩 이동하면서 convolution하게 됨

Image Kernels explained visually


- 원본 이미지에 특수한 행렬로 컨볼루션을 취함
- 행렬의 특성에 따라 원본 이미지로부터 특성이 강조된 이미지를 얻을 수 있음


https://cs231n.github.io/convolutional-networks/





CNN 이해
- 신경망의 높은 계층이 낮은 게층의 출력에 기반한 가중치가 적용된 합으로 형성됨
- 각 높은 계층의 뉴런은 낮은 계층의 특징들을 받아 이들의 가중합을 계산하고 이를 바탕으로 더 복잡한 특징을 인식
- Transfer Learning : 이미 대규모 데이터셋에서 사전 훈련된 모델의 지식을 새로운 문제에 적용하는 방법론으로 이때 낮은 계층의 일반적인 특징은 유지되고 높은 계층의 특징은 새로운 문제에 맞게 조정
- Capsule Network : 개별 뉴런 대신 "켑슐"이라 불리는 뉴런의 그룹을 사용하여 이미지 내 객체의 다양한 속성과 공간적인 관계를 보다 효과적으로 인식하는 신경망 구조
CNN 이해 - Padding
- Convolution Layer에서 Filter를 사용하여 Feature Map을 생성할 때, 이미지 크기가 작아지는 것을 막기 위해 테두리에 Filter 크기를 고려하여 특정 값(일반적으로 0)으로 채우는 작업
- 5x5 이미지에서 3x3 Filter를 사용하면 3x3 크기의 Feature Map이 만들어짐
즉, 5x5 이미지의 둘레에 0을 채워 7x7의 이미지로 만들어서 3x3 Filter를 적용해 5x5의 Feature Map을 얻음
- Padding 작업을 통해 인공신경망 이미지 외곽을 인식하도록 하는 효과도 있음 (필수 작업은 아님)

CNN 이해 - Pooling
- Convolution Layer의 Output을 Input으로 받아 Feature Map의 크기를 줄이거나 특정 데이터를 강조하는 용도로 사용
- Max Pooling, Min Pooling, Average Pooling 등의 종류가 있음
- Pooling Size를 Stride로 지정하며 이 크기에 따라 줄어드는 양이 줄어듬
- 입력 데이터의 행, 열 크기는 Pooling 사이즈의 배수(나누어 떨어지는 수)이어야 함

CNN 이해 - Filter & Pooling

CNN 이해 - Fully Connected Layer
- Flatten Layer : CNN의 데이터를 Fully Connected Neural Network의 형태로 변경하는 Layer
- 입력 데이터의 Shape 변경만 수행
- 입력 Shape이 (8, 8, 10)이면 Flatten이 적용된 Shape은 (640, 1)이 됨
- Softmax Layer : Flatten Layer의 출력을 입력으로 사요하며 분류 클래스에 매칭시키는 Layer
- 분류 작업을 실행해 결과를 얻게됨
- 입력 Shape이 (640, 1)이고 분류 클래스가 10인 경우 Softmax가 적용된 출력 Shape은 (10, 1)이 됨. 이때 weight의 shape은 (10, 640)이며 Softmax Layer의 parameter가 6,400개임

다양한 CNN 네트워크

전이학습의 필요성
- 딥러닝 모델 학습의 계산 자원과 시간
- MNIST 흑백 이미지 인식 모델 → 최소 3개의 convolution layer + 1개의 fully connected layer 필요
- CPU 환경에 따라 수 분~수십 분 소요됨
- CIFAR-10 고해상도 컬러 이미지 → 최소 5개의 convolution layer + 2개의 fully connected layer 필요
- 일반 CPU에서 수 시간~수십 시간 소요됨
- 최신 대규모 CNN 아키텍쳐(ResNet-152, EfficientNet-B7 등) → 수백 GPU 시간 + 대량의 데이터 필요함
- 전이학습의 해결책
- Pre-trained CNN 모델 활용 → 분석 데이터에 맞게 Fine-tuning
- 학습 시간 획기적 단축됨
- 데이터 부족 상황에서도 우수한 성능 확보 가능함
동작 원리
- 다른 도메인 간의 전이
- 동물 사진으로 학습한 모델 → 자동차/오토바이 분류에 활용 가능함
- 도메인 간 거리가 멀수록 효과는 감소함
- Fine-tuning 통해 우수한 성능 확보 가능함
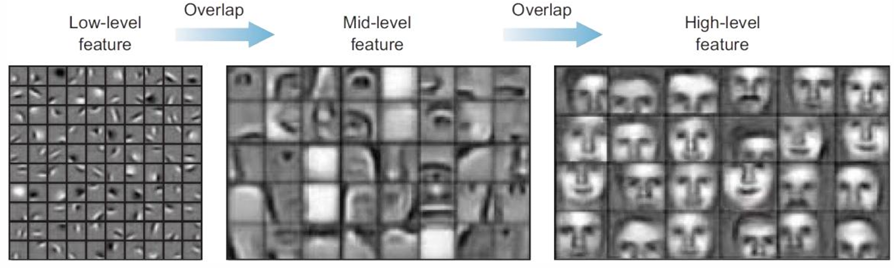
- 딥러닝 모델의 층별 특성
- 초기 층 → "일번적인(general)" 특징 추출함 (에지, 색상, 텍스처 등)
- 마지막 층 → "구체적인(specific)" 특징 추출함 (얼굴 특징, 특정 객체 부분 등)
- 시각적 특징 추출 과정
- 초기 층 → 수평선, 수직선, 에지, 단순 텍스처 감지함
- 중간 층 → 복잡한 패턴, 질감, 단순 형태 감지함
- 마지막 층 → 고수준 특징 (얼굴, 바퀴, 눈 등) 식별함
- 재사용 가능성
- 초기 층 → 다른 데이터셋에도 재사용 가능함
- 마지막 층 → 새로운 문제마다 새로 학습 필요함
**기계학습-신경망(CNN) 알아보기**
1. TensorFlow에서 사용하는 CNN 메서드 탐구하기
2. 데이터셋, 데이터 정규화, 모델, loss, accuracy의 개념을 정리하기
3. VGGNet 그림을 보고 직접 만들어보기
**[CNN 기반의 숫자 이미지 분류 - MNIST 데이터셋 활용_by Tensorflow]**
1.라이브러리 가져오기
# tensorflow 불러오기
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__)
2.데이터셋 로드 및 전처리하기
- MNIST는 0부터 9까지 숫자 손글씨로 이루어진 데이터셋으로\
28X28사이즈의 60000의 훈련 데이터와 10000개의 테스트 데이터로 구성되어 있습니다.
- x_train.shape == (60000, 28, 28)
- x_test.shape == (10000, 28, 28)
- y_train.shape == (60000,)
- y_test.shape == (10000,)

- Convolution Neural Network를 구성하고 있는 매개변수(Arguments)는 filters부터 bias_contraint까지 총 16개로 구성되어 있습니다.
- **filters** : 출력되는 결과의 차원수를 의미합니다.
- filter가 영향을 준 부분은 Tuple의 마지막 부분인 channel파트입니다. 즉 filter를 몇개 주는지에 따라서 channel수가 바뀌게 되고 이는 차원수가 바뀌는 것을 의미합니다.
- **kernel_size** : kernel_size가 위에 있는 코드는 3, 아래에 있는 코드는 2로 되어 있습니다. 그래서 output이 바뀐 파트는 Tuple의 2번째, 3번째에 영향을 줍니다.

위에 있는 gif를 보게 되면 빨간색 6x6 이미지를 3x3 filter를 이용해 convolution 연산이 진행되고 결과값은 보라색 이미지인 4x4이미지입니다.
해당 방식을 수학적으로 표현하면 다음과 같이 표현가능합니다.
output = input - filter + 1
- **strides**\ : strides는 filter 이동을 1개씩 가는 것이 아니라 n개씩 가도록 설정하는 매개변수입니다.

위에 있는 그림을 보게 되면 5x5 이미지를 3x3 filter가 2개씩 가도록 설정되어 있습니다.\
해당 설정을 하지 않았다면 output의 크기는 3x3이 되어야 하지만 stride가 설정되면서 2x2로 출력값이 나오게 되었습니다. 해당 내용도 코드로도 확인해보도록 하겠습니다.
stride가 적용되면 실제 output의 크기는 step만큼 나누어져서 계산됩니다.
그렇기에 stride가 적용된 output_shape은 다음과 같습니다.

- **padding**
- padding을 하는 이유는 filter는 가운데 파트는 몇번씩 거치면서 계산되지만 끝에 있는 edge부분은 한번밖에 계산되지 않습니다. 그렇기에 padding을 주어서 edge를 잘 볼 수 있게 하는 장치입니다.
- TensorFlow의 경우 padding은 '자동'으로 적용하며 'valid'는 적용하지 않은 것이며 'same'은 padding이 적용된 상황입니다.
padding이 적용되었을 때 Output shape은 다음과 같이 계산됩니다.

- **input_shape** : 처음 layer를 쌓을 떄 설정해주는 값이며
- **activation** : convolution 연산 이후 활성화함수를 고르는 매개변수입니다.
- 신경망 모델을 만들려면 모델의 층을 구성한 다음 모델을 컴파일합니다.
from tensorflow import keras
# 모델 아키텍처 정의
model = keras.Sequential([
# 입력 레이어 정의
keras.layers.Input(shape=(28, 28, 1)),
# 첫 번째 Convolution layer를 정의
keras.layers.Conv2D(16, (3, 3), activation='relu'),
# 두 번째MaxPooling2D layer 추가 (pooling size: (2, 2))
keras.layers.MaxPooling2D(pool_size=(2, 2)),
# 두 번째 Convolution layer 추가 (output 차원수: 32, filter 사이즈: 3, 활성화 함수: relu)
keras.layers.Conv2D(32, (3, 3), padding='same', activation='relu'),
# 두 번째 MaxPooling2D layer 추가
keras.layers.MaxPooling2D(pool_size=(2, 2)),
# 차원을 줄이는 Flatten layer 추가
keras.layers.Flatten(),
# Dense layer 추가 (output unit: 32, 활성화 함수: relu)
keras.layers.Dense(32, activation='relu'),
# 최종 Dense layer 추가 (output unit: 10, 활성화 함수: softmax)
keras.layers.Dense(10, activation='softmax')
])
# 모델 확인
model.summary()
# 모델 컴파일. 손실 함수, 옵티마이저, 메트릭 정의
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 훈련 데이터를 이용해 모델 학습
model.fit(train_images, train_labels, epochs=5)
# 테스트 데이터로 모델 평가. 손실과 정확도 출력
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('테스트 loss:', test_loss, '테스트 정확도:', test_acc)
# 예측 결과 시각화
predictions = model.predict(test_images)
num_rows = 3
num_cols = 3
num_images = num_rows * num_cols
plt.figure(figsize=(2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, num_cols, i+1)
plt.imshow(test_images[i], cmap=plt.cm.binary)
plt.xticks([])
plt.yticks([])
predicted_label = np.argmax(predictions[i])
true_label = test_labels[i]
if predicted_label == true_label:
color = 'green'
else:
color = 'red'
plt.xlabel("{} ({})".format(predicted_label, true_label), color=color)
plt.show()
이미지 데이터 수집


