
- 분류 전체보기 (426)

- C (66)
- C++ (45)
- Python (28)
- OpenCV (12)
- Arduino (21)
- Raspberry Pi (11)
- TCP IP 소켓 프로그래밍 (13)
- SQL (6)
- 대학교 2학년 1학기 (12)
- 대학교 2학년 2학기 (0)
- 대학교 3학년 1학기 (8)
- 대학교 3학년 2학기 (0)
- 대학교 4학년 1학기 (16)
- (두산로보틱스) ROKEY 부트 캠프 (113)
- (Telechips) AI 시스템 반도체 SW 개.. (74)
- C (9)
- C언어 ROS 문제 (1)
- C언어, Python, C++ 과제 문제 (0)
- ATmega128A 마이크로컨트롤러 프로그래밍 (12)
- ATmega128A mini Project (2)
- STM32CubeIDE (11)
- STM32CubeIDE mini Project (2)
- 비전과AI머신러닝 (17)
- MySQL & Visual Studio C 연동 .. (1)
- MFC Application (1)
- 비전과AI머신러닝 mini Project (1)
- SoC 시스템 반도체를 위한 온디바이스 AI (11)
- SoC 시스템 반도체를 위한 임베디드 리눅스 (6)
- OPIC 공부 (1)
printf("ho_tari\n");
16일차 본문
2025.05.12
시멘틱 세그멘테이션(Semantic Segmentation)
컴퓨터 비전 분야에서 중요한 과제 중 하나로, 이미지 내 각 픽셀을 해당하는 클래스에 매핑하는 기술임(예를 들어, 도시 풍경 사진에서 자동차, 건물, 도로 등의 각 객체를 픽셀 단위로 분류하여 특정 색상이나 라벨을 부여하는 작업이 이에 해당)
시멘틱 세그멘테이션의 사용 사례
1. 자율 주행 자동차: 도로에서 자동차, 보행자, 신호등, 도로 경계 등을 분류하여 안전한 주행을 돕습니다.
2. 의료 영상 분석: MRI나 CT 스캔에서 장기나 병변의 정확한 위치를 파악하고 진단에 활용됩니다.
3. 위성 이미지 분석: 농지, 도시, 산림 등의 영역을 파악하여 지리적 변화를 감시합니다.
주요 알고리즘 소개
1. **Fully Convolutional Network (FCN)**: 모든 계층을 convolutional layer로 구성하여 이미지를 픽셀 단위로 분류하는 최초의 신경망 구조입니다. 기존의 이미지 분류용 네트워크를 기반으로 하며, 마지막 레이어에서 픽셀마다 클래스 스코어를 예측합니다.
2. Encoder-Decoder 구조
- Encoder는 이미지를 받아 고차원 특징을 추출하는 부분입니다. 깊은 신경망을 통해 점진적으로 공간 정보를 압축하면서 중요한 특징을 추출합니다.
- Decoder는 압축된 특징을 사용해 고해상도로 복원하는 부분입니다. 주로 업샘플링 과정을 통해 입력 크기로 복원하며, 픽셀 단위로 분류를 수행합니다.
- Skip Connection: 일반적으로 Encoder-Decoder 구조에서 활용. 단순한 Encoder-Decoder 구조의 경우 공간 정보를 압축하는 과정에서 해상도가 손실되는데 이를 보완하기 위해 Encoder에서 추출된 저차원 특징을 Decoder에 직접 연결하여 결합함으로써 보다 정확한 픽셀 분류가 가능하도록 합니다.
예시 알고리즘
- UNet: 의료 영상 분야에서 잘 알려진 알고리즘으로, 고해상도의 세그멘테이션을 위한 효과적인 구조를 갖추고 있습니다. Encoder-Decoder 구조와 함께 skip connection을 활용합니다.
- DeepLab: 디렉셔널 필터링과 아트리션 컨볼루션을 활용하여 객체 경계를 세밀하게 분리합니다.

R-CNN: https://arxiv.org/abs/1311.2524
- 객체 탐지에 사용된 초기 모델
- 주요 객체들을 바운딩 박스로 표현하여 정확히 식별하는게 목표
- Selective Search를 통해 다양한 크기의 박스를 만들고, region proposal 영역 생성
- region proposal 영역을 warp하여 표준화된 크기로 변환
- AlexNet을 개량한 CNN 모델을 이용하고, 마지막 층에 SVM을 통해 객체 분류
Fast R-CNN: https://arxiv.org/abs/1504.08083
- R-CNN의 단점인 느린 속도를 빠른 속도로 개선
- ROI(Region of Interest) 풀링을 통해 한 이미지의 subregion에 대한 forward pass 값을 공유
- R-CNN은 CNN 모델로 image feature를 추출, SVM 모델로 분류, Regressor 모델로 bounding box를 맞추는 작업으로 분류되어 있지만, Fast R-CNN은 하나의 모델로 동작
- Top layer에 softmax layer를 둬서 CNN 결과를 class로 출력
- Box regression layer를 softmax layer에 평행하게 두어 bounding box 좌표를 출력

Faster R-CNN: https://arxiv.org/abs/1506.01497
- Fast R-CNN은 가능성 있는 다양한 bounding box들, 즉 ROI를 생성하는 과정인 selective search가 느려 region proposer에서 병목이 발생
- 이미지 분류(classification)의 첫 단계인 CNN의 forward pass를 통해 얻어진 feature들을 기반으로 영역을 제안
- CNN 결과를 selective search 알고리즘 대신 region proposal에 이용
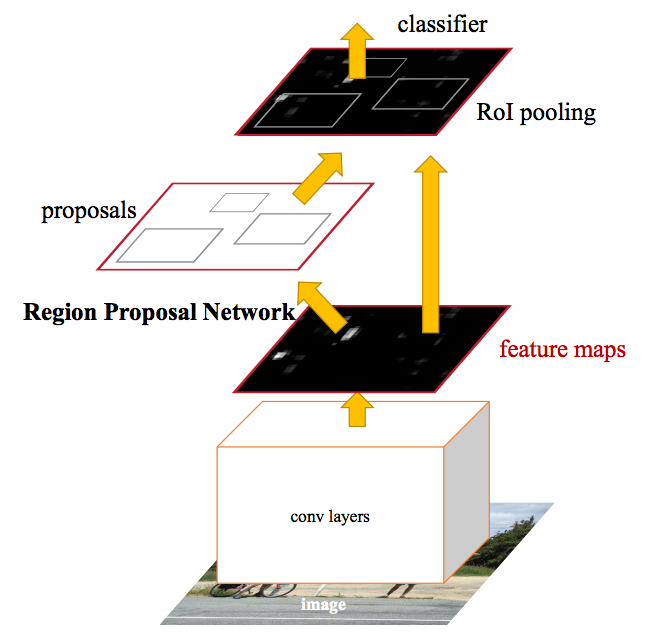
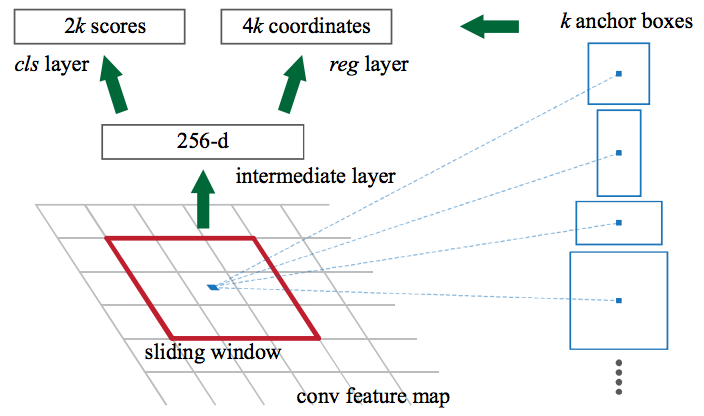
- k개의 일반적인 비율을 지닌 anchor box를 이용하여 하나의 bounding box 및 score를 이미지의 위치별로 출력
Mask R-CNN: https://arxiv.org/abs/1703.06870
- Pixel 레벨의 세그멘테이션
- RolPool에서 선택된 feature map이 원래 이미지 영역으로 약간 잘못된 정렬이 발생한 부분을 RolAlign을 통해 조정하여 정확하게 정렬
- Mask R-CNN은 Mask가 생성되면, Faster R-CNN으로 생성된 classification과 bounding box들을 합쳐 정확한 세그멘테이션 가능
U-Net 기반 세그멘테이션
- 사용된 모델은 수정된 U-Net(https://arxiv.org/abs/1505.04597)
- U-Net이라 불리는 인코더(다운샘플링- Contracting Path:피처맵의 크기가 줄어듬, 572-> 284->140->68->332->30)와 디코더(업샘플링-expanding path:피처맵의 크기가 커)를 포함한 구조는 정교한 픽셀 단위의 segmentation이 요구되는 biomedical image segmentation task의 핵심 요소
- 다운샘플링과정에서 피처맵 사이즈는 줄어드나 채널의 수는 증가하기 때문에 압축되는 과정에서 정보가 손실된다기보다 다른 형태로 추출한다고 생각할 수 있음
- 최종 output 이 2 는 388*388 피처에서 binary classifcation 진행
- Encoder-decoder 구조 또한 semantic segmentation을 위한 CNN 구조로 자주 활용
- Encoder 부분에서는 점진적으로 spatial dimension을 줄여가면서 고차원의 semantic 정보를 convolution filter가 추출해낼 수 있게 함
- Decoder 부분에서는 encoder에서 spatial dimension 축소로 인해 손실된 spatial 정보를 점진적으로 복원하여 보다 정교한 boundary segmentation을 완성
- Skip connection : input -> output 채널 방향으로 concatenate 함 (다운샘플링과 업샘플링을 거친값과 입력 X 값을 그대로 가져와 둘 다 활용)
- U-Net은 기본적인 encoder-decoder 구조와 달리 Spatial 정보를 복원하는 과정에서 이전 encoder feature map 중 동일한 크기를 지닌 feature map을 가져 와 prior로 활용함으로써 더 정확한 boundary segmentation이 가능하게 함

Oxford-IIIT Pets 데이터셋
- Parkhi et al이 만든 [Oxford-IIIT Pet Dataset](https://www.robots.ox.ac.uk/~vgg/data/pets/) 데이터 세트는 영상, 해당 레이블과 픽셀 단위의 마스크로 구성
- 마스크는 기본적으로 각 픽셀의 레이블
- 각 픽셀은 다음 세 가지 범주 중 하나
* class 1 : 애완동물이 속한 픽셀
* class 2 : 애완동물과 인접한 픽셀
* class 3 : 위에 속하지 않는 경우/주변 픽셀
- Images: https://www.robots.ox.ac.uk/~vgg/data/pets/data/images.tar.gz
- Annotations: https://www.robots.ox.ac.uk/~vgg/data/pets/data/annotations.tar.gz
DeepLab 기반 세그멘테이션
DeepLab V1: [Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs](https://arxiv.org/abs/1412.7062), ICLR 2015.
- Atrous convolution은 기존 convolution과 다르게 필터 내부에 빈 공간을 둔 채로 작동
- 기존 convolution과 동일한 양의 파라미터와 계산량을 유지하면서 field of view (한 픽셀이 볼 수 있는 영역)를 크게 가져갈 수 있음
- Semantic segmentation에서 일반적으로 높은 성능을 내기 위해서는 convolutional neural network의 마지막에 존재하는 한 픽셀이 입력값에서 어느 크기의 영역을 커버할 수 있는지를 결정하는 receptive field 크기가 중요
- Atrous convolution을 활용하면 파라미터 수를 늘리지 않으면서도 receptive field를 크게 키울 수 있기 때문에 DeepLab 계열에서는 이를 적극적으로 활용

DeepLab V2: [DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs](https://arxiv.org/abs/1606.00915), TPAMI 2017.
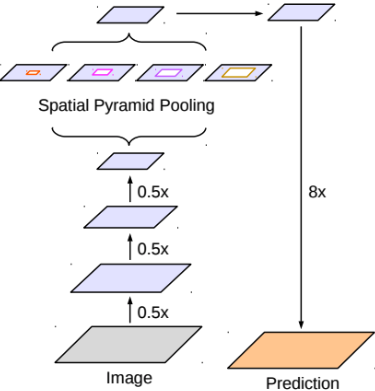
- Semantic segmentaion의 성능을 높이기 위한 방법 중 하나로, spatial pyramid pooling 기법을 자주 사용
- Feature map으로부터 여러 개의 rate가 다른 atrous convolution을 병렬로 적용한 뒤, 이를 다시 합쳐주는 atrous spatial pyramid pooling (ASPP) 기법을 활용
- multi-scale context를 모델 구조로 구현하여 보다 정확한 semantic segmentation을 수행할 수 있도록 함
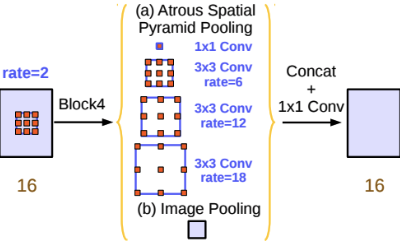
DeepLab V3: [Rethinking Atrous Convolution for Semantic Image Segmentation](https://arxiv.org/abs/1706.05587), arXiv 2017.
- Encoder: ResNet with Atrous convolution
- Atrous Spatial Pyramid Pooling (ASPP)
- Decoder: Bilinear Upsampling
DeepLab V3+: [Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation](https://arxiv.org/pdf/1802.02611.pdf), arXiv 2018.
- Encoder: ResNet with Atrous Convolution → Xception (Inception with Separable Convolution)
- ASPP → ASSPP (Atrous Separable Spatial Pyramid Pooling)
- Decoder: Bilinear Upsampling → Simplified U-Net style decoder

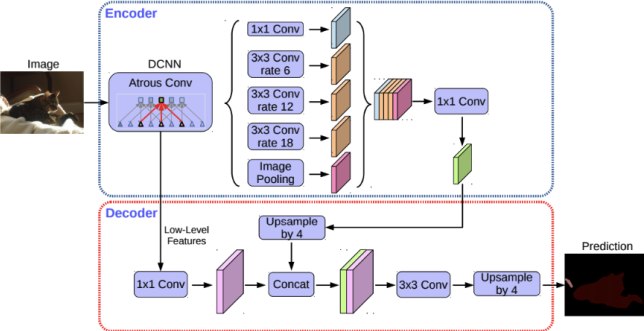
모델 구성
인코더-디코더 구조를 확장
인코더 모듈: 확장된 컨볼루션을 여러 척도로 적용하여 다중 스케일 상황 정보 처리
디코더 모듈: 객체 경계를 따라 분할 결과 조정
확장된 컨볼루션(Dilated convolution)
- 컨볼루션 확장을 통해 네트워크 깊숙히 들어가며 스트라이드를 일정하게 유지 가능
- 매개변수의 수나 계산량을 늘리지 않고도 더 큰 시야를 가질 수 있음
- 더 큰 특징 맵 출력이 가능하여 세그멘테이션에 유용함
확장된 공간 피라미드 풀링(Dilated Spatial Pyramid Pooling)
- 샘플링 속도가 커질수록 유효한 필터 가중치(유효한 특징 영역에 적용되는 가중치)의 수가 작아짐
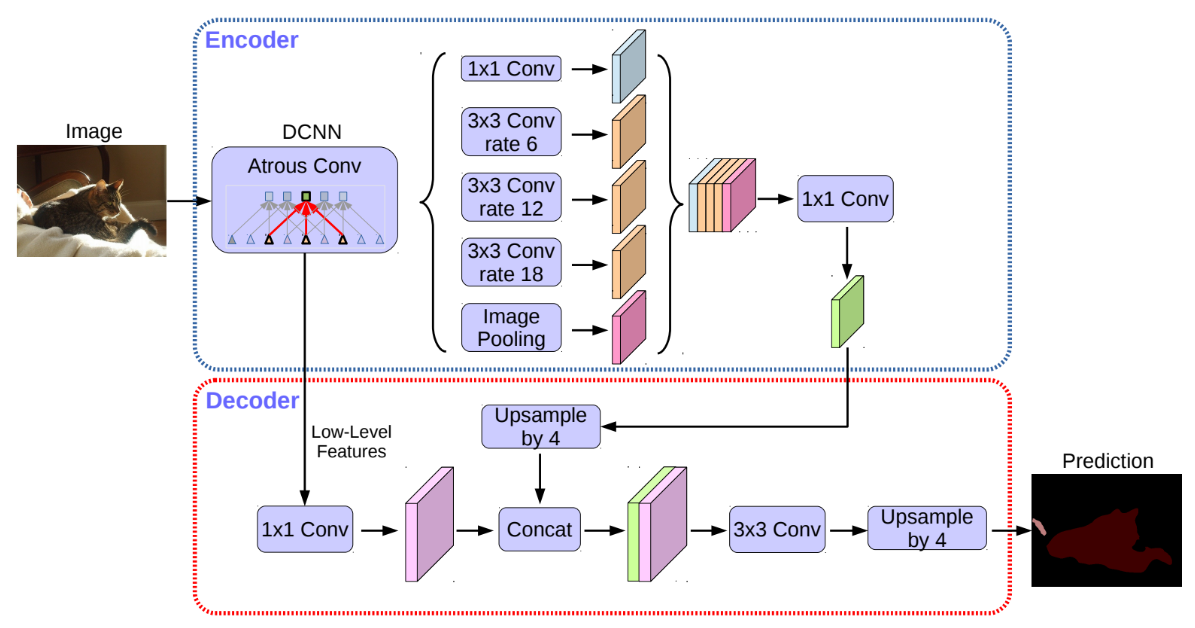
사전 훈련된 ResNet50을 백본 모델로 사용
`conv4_block6_2_relu` 블록에서 저수준의 특징 사용
인코더 특징은 인자 4에 의해 쌍선형 업샘플링
동일한 공간 해상도를 가진 네트워크 백본에서 저수준 특징과 연결
Detectron Mask R-CNN
페이스북 인공지능 연구소(FAIR)에서 공개한 플랫폼
빠르고 유연한 사물 탐지 가능

Detectron2

페이스북 인공지능 연구소(FAIR)에서 개발한 객체 세그멘테이션 프레임워크
페이스북에서 개발한 DensePose, Mask R-CNN 등을 Detectron2에서 제공
손쉽게 다양한 사물들을 탐지하고 세그먼테이션하여, 객체의 유형, 크기, 위치 등을 자동으로 얻을 수 있음
ObjectDetection : Custom Datasets 만들기
< Object Detection을 위한 Custom Datasets 만들기 >
1. Data Labelling 도구
2. CVAT 을 사용하여 Annotation 하기
1) Project 생성하기
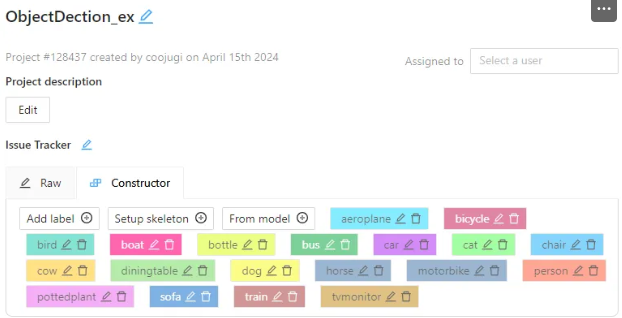
2) Project Name 지정 후 [ Constructor] 탭에서 label 생성하기
-
- ② ~ ⑤ 번까지 반복하여 20개의 label 생성하기 : 색상은 각기 다르게 지정
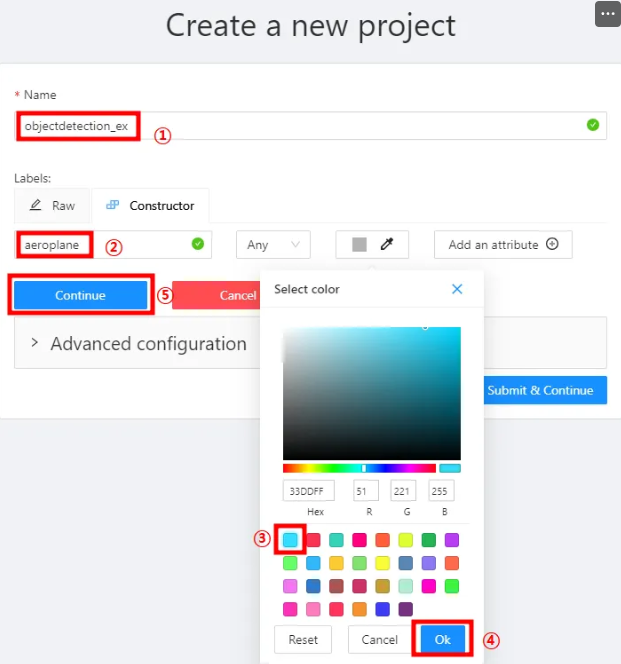
- 20개 label :

- 20개의 label 생성 후 “Submit & Open” 버튼 클릭하기
3) Task 생성하기
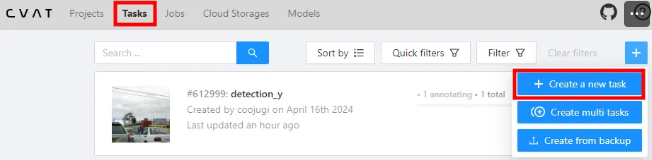

- 압축파일 해제하여 file upload하기
- “Submit & Open” 클릭하기
- Task 목록에서 생성된 Task를 open 한 후 Jobs 실행하기
- Job 번호 클릭하기

- labelling 진행하기

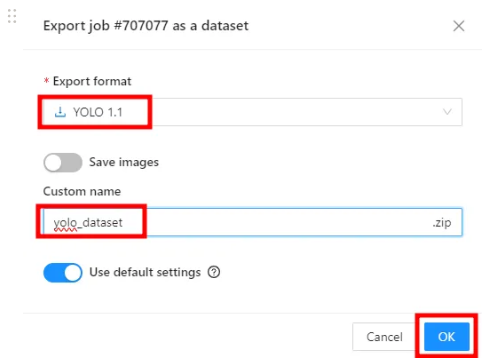
- 5장의 이미지의 labelling 완료되면 상단 ‘Save” 버튼 후 “Export job dataset” 클릭하기

- 내보내기 형식 지정하고 이름 지정후 “OK” 클릭하기
3. Roboflow 을 사용하여 Annotation 하기
1) 프로젝트 생성하기 : New Project
2) 데이터파일 업로드하기 : Upload Data
3) 클래스 등록하기
4) 어노테이팅하기 : Start Annotation
5) 버전 생성하기 : 3~5번 단계까지 진행하기
6) 데이터셋 다운로드하기
'(Telechips) AI 시스템 반도체 SW 개발자 교육 > 비전과AI머신러닝' 카테고리의 다른 글
| Mini Project1 - No Smoking Area Project (with YOLOv8) (0) | 2025.05.13 |
|---|---|
| 15일차 (0) | 2025.05.09 |
| 14일차 (0) | 2025.05.08 |
| 13일차 (0) | 2025.05.07 |
| 12일차 (0) | 2025.04.29 |


