

printf("ho_tari\n");
PCA #5 본문
<코드>
from keras.models import Sequential
from keras.layers import Dense
from keras.datasets import mnist
from keras.utils import to_categorical
# 데이터셋 로드 및 전처리
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
L, W, H = train_images.shape
train_images = train_images.reshape((60000, W * H))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((10000, W * H))
test_images = test_images.astype('float32') / 255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
# 모델 구성
model = Sequential()
model.add(Dense(10, activation='softmax', input_shape=(W * H,)))
# 모델 컴파일
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
# 모델 학습
history = model.fit(train_images, train_labels, epochs=20, batch_size=100, validation_split=0.2)
# 학습 결과 출력
import matplotlib.pyplot as plt
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'r', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Accuracy')
plt.legend()
plt.show()
Problem #1
1 layer NN으로 MNIST데이터셋을 분류하고자 한다. Sequential()을 이용하여 모델을 구성하는 코드를 작성하세요.
We want to use a 1-layer NN for MNIST classification. Please show the keras implementation using Sequential().

Problem #2
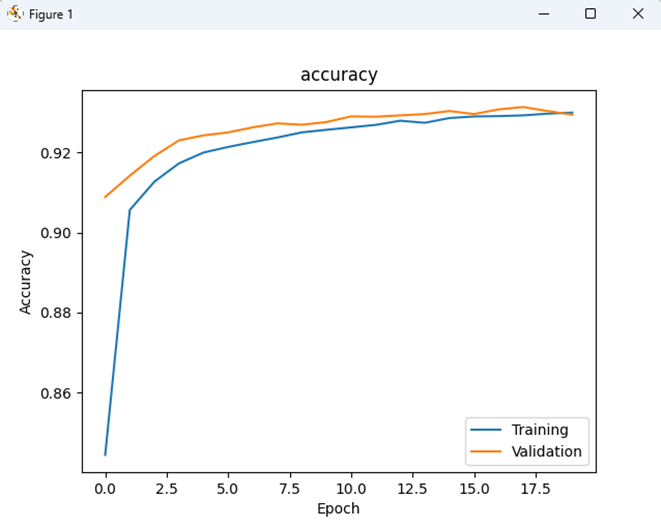
Epoch을 20으로 했을 때 Learning Curve (accuracy)를 보여주세요.
Show the learning curve of accuracy with epochs=20.
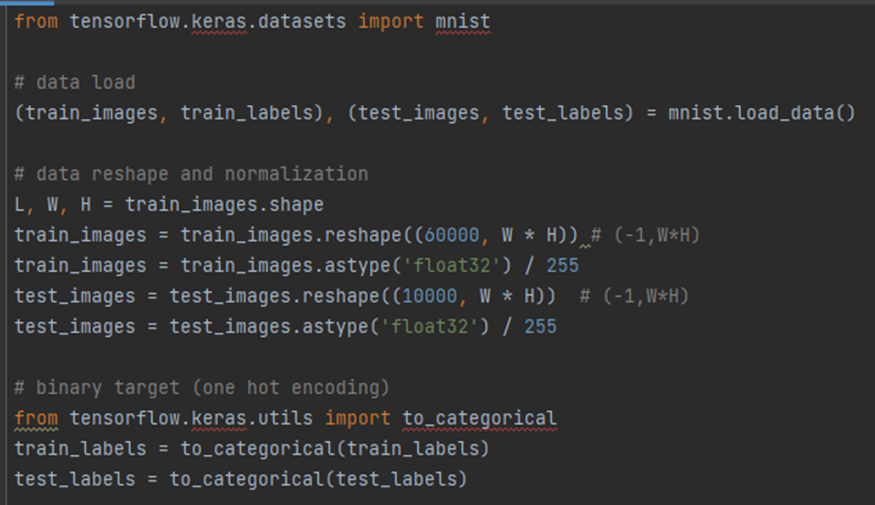
<Load and Preprocess data 코드>
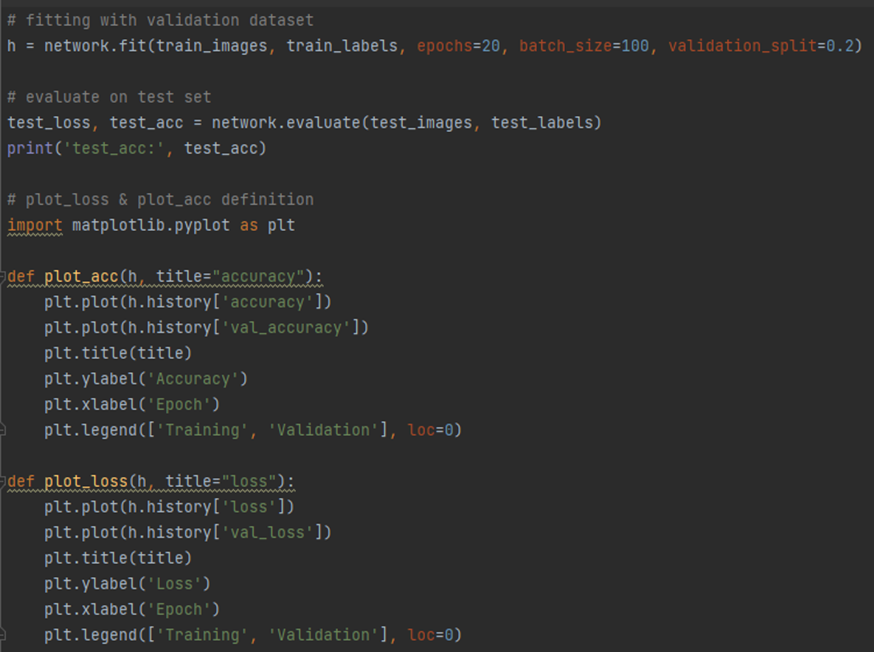
<Training and Evaluation 코드>
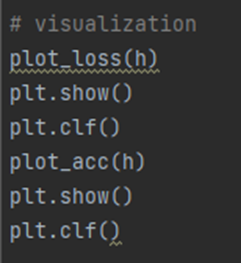
<Visualization 코드>
Problem #3
트레이닝 데이터셋에 50000개의 데이터가 있다 validation split을 0.2로 지정하고 mini-bath size를 100으로 지정하면, 1 epoch당 weight update는 몇번이나 일어나는가?
Assume that we have 50000 samples in the training data set. If you use validation split=0.2, and batch_size=100, how many weight updates occurs during 1 epoch?
Validation split을 0.2로 지정하면 20%의 트레이닝 데이터셋이 검증 데이터셋으로 사용되므로 50000 * 0.8 = 40000개의 데이터가 포함됩니다.
또한, mini-batch size를 100으로 지정해주었으므로
1 epoch 당 weight update는 40000 / 100 = 400번 일어납니다.



