
printf("ho_tari\n");
ep.39 OpenCV5 본문
2024.8.30
8장 영상 매칭과 추적
영상 매칭이란 서로 다른 두 이미지를 비교해서 짝이 맞는 같은 형태의 객체가 있는지 찾아내는 기술을 말합니다.
이미지에서 객체를 찾는 방법은 이미지에서 의미 있는 특징들을 적절한 숫자로 변환하고 그 숫자들을 서로 비교해서 얼마나 비슷한지 판단하는 것입니다.
쉽게 말해 두 이미지 간 유사도를 측정하는 작업입니다. 특징을 대표할 수 있는 숫자를 특징 벡터 혹은 특징 디스크립터라고 합니다.
이미지 매칭은 큰 주제이므로 이에 대해서는 앞으로 계속 포스팅할 예정입니다.
8.1 비슷한 그림 찾기
8.1.1 평균 해시 매칭
평균 해시 매칭은 이미지 매칭의 한 기법인데, 효과는 떨어지지만 구현이 아주 간단합니다.
평균 해시 매칭은 특징 벡터를 구하기 위해 평균값을 사용합니다.
우선, 두 이미지 사이에서 비슷한 그림을 찾기 전에 찾고자 하는 그림의 특징 벡터를 구하는 방법에 대해 알아보겠습니다.
이미지를 가로 세로 비율과 무관하게 특정한 크기로 축소합니다.
픽셀 전체의 평균값을 구해서 각 픽셀의 값이 평균보다 작으면 0, 크면 1로 바꿉니다.
0 또는 1로만 구성된 각 픽셀 값을 1행 1열로 변환합니다.
(이는 한 개의 2진수 숫자로 볼 수 있습니다.)
이때 비교를 하고자 하는 두 이미지를 같은 크기로 축소해야 합니다. 그렇기 때문에 0과 1의 개수도 동일합니다.
(2진수로 표현했을 때 비트 개수가 같다고 볼 수 있습니다.)
2진수가 너무 길어서 보기 불편하다면 필요에 따라 10진수나 16진수 등으로 변환해서 사용할 수 있습니다.
다음은 권총 이미지를 16 x 16 크기의 평균 해시로 변환하여 특징 벡터를 구하는 코드입니다.
앞서 설명드린 프로세스에 따라서 우선 이미지를 16 x 16 사이즈로 조정합니다.
그런 다음 픽셀의 전체 평균값을 구하고 그 평균값보다 큰 픽셀은 1, 작은 픽셀은 0으로 바꿉니다. 그렇게 구한 결과가 0과 1로 구성된 배열입니다.
숫자 배열을 자세히 보시면 0으로 구성된 부분이 권총 모양을 닮았음을 알 수 있습니다. 권총은 검은색이므로 픽셀 값이 0에 가깝고, 배경은 픽셀 값이 255에 가깝습니다.
따라서 전체 픽셀의 평균값보다 작은 부분은 0, 큰 부분은 1로 바뀐 것입니다.
이제 이렇게 얻은 평균 해시를 다른 이미지의 것과 비교해서 얼마나 비슷한지를 알아내야 합니다.
비슷한 정도를 측정하는 방법에는 여러 가지가 있습니다.
그중 가장 대표적인 것이 유클리드 거리(Euclidian distance)와 해밍 거리(Hamming distance)입니다.
유클리드 거리는 두 값의 차이로 거리를 계산합니다. 예를 들어 5와 비교할 값으로 1과 7이 있다면 5와 1의 유클리드 거리는 5-1 = 4이고, 5와 7의 유클리드 거리는 7-5 = 2입니다.
유클리드 거리가 작을수록 두 수는 비슷한 수라고 판단하므로 5는 1보다는 7과 더 유사하다고 결론짓습니다.
해밍 거리는 두 값의 길이가 같아야 계산할 수 있습니다.
해밍 거리는 두 수의 같은 자리 값 중 서로 다른 것이 몇 개인지를 판단하여 유사도를 계산합니다.
예를 들어 12345와 비교할 값으로 12354와 92345가 있을 때 12345와 12354의 마지막 자리가 45와 54로 다르므로 해밍 거리는 2입니다.
반면 12345와 92345는 1과 9 한자리만 다르므로 해밍 거리는 1입니다. 따라서 12345는 12354보다 92345와 더 유사하다고 판단합니다.
앞서 구한 권총의 평균 해시를 다른 이미지와 비교할 때는 해밍 거리를 써야 합니다.
유클리드 거리는 자릿수가 높을수록 차이가 크게 벌어지지만 해밍 거리는 몇 개의 숫자가 다른가만을 고려하기 때문입니다.
이미지를 비교하는데 평균 해시 숫자의 크기가 중요하기보다는 얼마나 유사한 자릿수가 많은지가 더 중요합니다.
이제 권총 이미지의 평균 해시를 다른 이미지의 평균 해시와 해밍 거리로 비교해 유사도를 측정해보겠습니다.

8.1.2 템플릿 매칭
템플릿 매칭은 특정 물체에 대한 이미지를 준비해 두고 그 물체가 포함되어 있을 것이라고 예상할 수 있는 이미지와 비교하여 매칭 되는 위치를 찾는 것입니다.
이때 미리 준비한 이미지를 템플릿 이미지라고 합니다.
템플릿 이미지는 비교할 이미지보다 크기가 항상 작아야 합니다.
템플릿 매칭과 관련한 함수는 다음과 같습니다.
result = cv2.matchTemplate(img, templ, method, result, mask)
- img: 입력 이미지
- templ: 템플릿 이미지
- method: 매칭 메서드
- cv2.TM_SQDIFF: 제곱 차이 매칭, 완벽 매칭:0, 나쁜 매칭: 큰 값
- cv2.TM_SQDIFF_NORMED: 제곱 차이 매칭의 정규화
- cv2.TM_CCORR: 상관관계 매칭, 완벽 매칭: 큰 값, 나쁜 매칭: 0
- cv2.TM_CCORR_NORMED: 상관관계 매칭의 정규화
- cv2.TM_CCOEFF: 상관계수 매칭, 완벽 매칭:1, 나쁜 매칭: -1
- cv2.TM_CCOEFF_NORMED: 상관계수 매칭의 정규화)
- result(optional): 매칭 결과, (W - w + 1) x (H - h + 1) 크기의 2차원 배열 [여기서 W, H는 입력 이미지의 너비와 높이, w, h는 템플릿 이미지의 너비와 높이]
- mask(optional): TM_SQDIFF, TM_CCORR_NORMED인 경우 사용할 마스크
minVal, maxVal, minLoc, maxLoc = cv2.minMaxLoc(src, mask)
- src: 입력 1 채널 배열
- minVal, maxVal: 배열 전체에서의 최소 값, 최대 값
- minLoc, maxLoc: 최소 값과 최대 값의 좌표 (x, y)
cv2.matchTemplate() 함수는 입력 이미지(img)에서 템플릿 이미지(templ)를 슬라이딩하면서 주어진 메서드에 따라 매칭을 수행합니다.
cv2.matchTemplate() 함수의 반환 값은 (W - w + 1) x (H - h + 1) 크기의 2차원 배열입니다.
(여기서 W, H는 입력 이미지의 너비와 높이, w, h는 템플릿 이미지의 너비와 높이입니다.)
이 배열의 최솟값 혹은 최댓값을 구하면 원하는 최선의 매칭값과 매칭점을 구할 수 있습니다.
이것을 손쉽게 해주는 함수가 바로 cv2.minMaxLoc()입니다. 이 함수는 입력 배열에서의 최솟값, 최댓값뿐만 아니라 최솟값, 최댓값의 좌표도 반환합니다.
아래는 로봇 태권 V를 다른 이미지 내에서 템플릿 매칭 방식으로 찾는 예시 코드입니다.
8.2 영상의 특징과 키 포인트
8.1에서 다룬 특징 추출과 매칭 방법은 이미지 전체를 전역적으로 반영하는 방법입니다.
전역적으로 반영하기 위해서는 비교하려는 두 이미지 내 물체가 거의 비슷한 모양을 가지고 있어야 합니다.
크기가 다르다거나 회전을 했다거나 방향이 다르면 효과가 없습니다. 이런 경우 이미지를 검출하기 위해서는 이미지의 특징점을 찾아내야 합니다.
8.2.1 코너 특징 검출
이미지 특징점이란 말 그대로 이미지에서 특징이 되는 부분을 의미합니다.
이미지끼리 서로 매칭이 되는지 확인을 할 때 각 이미지에서의 특징이 되는 부분끼리 비교를 합니다.
즉, 이미지 매칭 시 사용하는 것이 바로 특징점입니다.
특징점은 영어로 키 포인트(Keypoints)라고도 합니다.
보통 특징점이 되는 부분은 물체의 모서리나 코너입니다.
그래서 대부분의 특징점 검출을 코너 검출을 바탕으로 하고 있습니다.
사각형을 사각형이라고 인지할 수 있는 건 4개의 꼭짓점이 있기 때문입니다.
삼각형도 3개의 꼭짓점이 있기 때문에 삼각형이라고 인지할 수 있습니다.
마찬가지로 우리가 어떤 물체를 볼 때 꼭짓점을 더 유심히 보는 경향이 있습니다.
즉 물체를 인식할 때 물체의 코너 부분에 관심을 둡니다. 이미지 상의 코너를 잘 찾아낸다면 물체를 보다 쉽게 인식할 수 있을 것입니다.
코너를 검출하기 위한 방법으로는 해리스 코너 검출(Harris corner detection)이 있습니다.
해리스 코너 검출은 소벨(Sobel) 미분으로 경곗값을 검출하면서 경곗값의 경사도 변화량을 측정하여 변화량이 수직, 수평, 대각선 방향으로 크게 변화하는 것을 코너로 판단합니다.
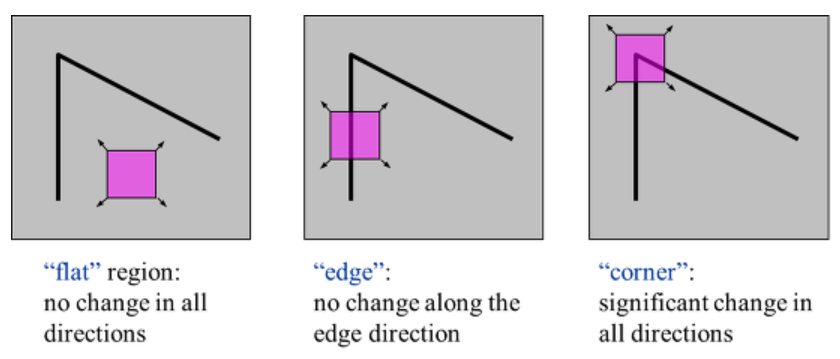
OpenCV에서는 다음의 함수로 해리스 코너 검출 기능을 제공합니다.
dst = cv2.cornerHarris(src, blockSize, ksize, k, dst, borderType)
- src: 입력 이미지, 그레이 스케일
- blockSize: 이웃 픽셀 범위
- ksize: 소벨 미분 필터 크기
- k(optional): 코너 검출 상수 (보토 0.04~0.06)
- dst(optional): 코너 검출 결과 (src와 같은 크기의 1 채널 배열, 변화량의 값, 지역 최대 값이 코너점을 의미) borderType(optional): 외곽 영역 보정 형식
시-토미시 검출(Shi & Tomasi Detection)
해리스 코너 검출을 좀 더 개선한 알고리즘도 있습니다.
시-토마시 코너 검출 방법인데, 이를 OpenCV에서는 다음 함수로 제공합니다.
corners = cv2.goodFeaturesToTrack(img, maxCorners, qualityLevel, minDistance, corners, mask, blockSize, useHarrisDetector, k)
- img : 입력 이미지
- maxCorners : 얻고 싶은 코너의 개수, 강한 것 순으로
- qualityLevel : 코너로 판단할 스레시홀드 값
- minDistance : 코너 간 최소 거리
- mask(optional) : 검출에 제외할 마스크
- blockSize(optional)=3: 코너 주변 영역의 크기
- useHarrisDetector(optional)=False: 코너 검출 방법 선택
- True: 해리스 코너 검출 방법
- False: 시와 토마시 코너 검출 방법)
- k(optional): 해리스 코너 검출 방법에 사용할 k 계수
- corners: 코너 검출 좌표 결과, N x 1 x 2 크기의 배열, 실수 값이므로 정수로 변형 필요
useHarrisDetector 파라미터에 True를 전달하면 해리스 코너 검출을 하고, 디폴트 값인 False를 전달하면 시와 토마시 코너 검출을 합니다.
해리스 코너 검출에서 사용했던 동일한 이미지로 시-토마시 코너 검출을 해보겠습니다.
8.2.2 키 포인트와 특징 검출기
특징점 검출을 위한 알고리즘은 다양합니다.
또한 각각의 특징점도 좌표(x, y) 이외에 다양한 정보를 가집니다.
위에서 살펴봤던 해리스 코너 검출과 시-토마시 검출의 함수 반환 결과는 단지 특징점의 좌표였습니다.
하지만 앞으로 배울 특징점 검출기들의 반환 결과는 특징점의 좌표뿐만 아니라 다양한 정보들도 함께 반환합니다.
OpenCV는 아래와 같은 특징점 검출 함수를 제공합니다. (detector에 각 특징점 검출기 함수를 대입하면 됩니다.)
keypoints = detector.detect(img, mask): 특징점 검출 함수
- img : 입력 이미지
- mask(optional) : 검출 제외 마스크
- keypoints : 특징점 검출 결과 (KeyPoint의 리스트)
- Keypoint : 특징점 정보를 담는 객체
- pt : 특징점 좌표(x, y), float 타입으로 정수 변환 필요
- size : 의미 있는 특징점 이웃의 반지름
- angle : 특징점 방향 (시계방향, -1=의미 없음)
- response : 특징점 반응 강도 (추출기에 따라 다름)
- octave : 발견된 이미지 피라미드 계층
- class_id : 특징점이 속한 객체 ID
말씀드렸다시피 detector.detect() 함수의 반환 결과인 Keypoints에는 다양한 정보들이 담겨있습니다.
Keypoints는 특징점의 좌표 정보인 pt 속성을 항상 갖지만 나머지 속성은 사용하는 검출기에 따라 반환하지 않을 수도 있습니다.
검출한 특징점은 앞선 예제와 마찬가지로 cv2.circle() 함수를 사용해서 표시할 수도 있지만 OpenCV에서는 아래와 같이 특징점을 표시해주는 전용 함수를 제공합니다.
outImg = cv2.drawKeypoints(img, keypoints, outImg, color, flags)
- img: 입력 이미지
- keypoints: 표시할 특징점 리스트
- outImg: 특징점이 그려진 결과 이미지
- color(optional): 표시할 색상 (default: 랜덤)
- flags(optional): 표시 방법
- cv2.DRAW_MATCHES_FLAGS_DEFAULT: 좌표 중심에 동그라미만 그림(default)
- cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS: 동그라미의 크기를 size와 angle을 반영해서 그림
8.2.3 GFTTDetector
GFTTDetector는 앞서 살펴본 cv2.goodFeaturesToTrack() 함수로 구현된 특징점 검출기입니다.
GFTTDetector 함수의 생성은 아래와 같이 하고, GFTTDetector 검출기를 활용하여 특징점을 검출하는데 사용하는 함수는 바로 위에서 소개한 detect() 함수와 같습니다.
detector = cv2.GFTTDetector_create(img, maxCorners, qualityLevel, minDistance, corners, mask, blockSize, useHarrisDetector, k)
- 모든 파라미터는 cv2.goodFeaturesToTrack()과 동일
이 검출기로 검출한 결과는 특징점 좌표(pt) 속성만 있고 나머지 속성 값은 모두 비어 있습니다.
8.2.4 FAST
FAST는 기존 검출기보다 속도가 빠른 검출기입니다.
FAST 검출기는 코너를 검출할 때 미분 연산을 하지 않습니다.
대신 픽셀을 중심으로 특정 개수의 픽셀로 원을 그려서 그 안의 픽셀들이 중심 픽셀 값보다 임계 값 이상 밝거나 어두운 것이 일정 개수 이상 연속되면 코너로 판단합니다.
다시 말해 어떤 점 p가 특징점인지 여부를 판단할 때, p를 중심으로 하는 원 상이 16개 픽셀 값을 봅니다.
p보다 임계 값 이상 밝은 픽셀들이 n개 이상 연속되어 있거나 또는 임계 값 이상 어두운 픽셀들이 n개 이상 연속되어 있으면 p를 특징점이라고 판단합니다.

OpenCV에서 제공하는 FAST 함수는 아래와 같이 생성합니다. 역시나 특징점 검출 시에는 detect() 함수를 사용합니다.
detector = cv2.FastFeatureDetector_create(threshold, nonmaxSuppression, type)
- threshold(optional): 코너 판단 임계 값 (default=10)
- nonmaxSuppression(optional): 최대 점수가 아닌 코너 억제 (default=True)
- type(optional): 엣지 검출 패턴
- cv2.FastFeatureDetector_TYPE_9_16: 16개 중 9개 연속(default)
- cv2.FastFeatureDetector_TYPE_7_12: 12개 중 7개 연속
- cv2.FastFeatureDetector_TYPE_5_8: 8개 중 5개 연속)
8.2.5 SimpleBlobDetector
BLOB(Binary Large Object)는 이진 스케일로 연결된 픽셀 그룹을 말합니다.
SimpleBlobDetector는 자잘한 객체는 노이즈로 여기고 특정 크기 이상의 큰 객체만 찾아내는 검출기입니다.
SimpleBlobDetector는 아래와 같이 생성합니다.
detector = cv2.SimpleBlobDetector_create([parameters]) : BLOB 검출기 생성자 parametes는 다음과 같습니다.
- cv2.SimpleBlobDetector_Params()
- minThreshold, maxThreshold, thresholdStep: BLOB를 생성하기 위한 경계 값
- minThreshold에서 maxThreshold를 넘지 않을 때까지 thresholdStep만큼 증가
- minRepeatability: BLOB에 참여하기 위한 연속된 경계 값의 개수
- minDistBetweenBlobs: 두 BLOB을 하나의 BLOB으로 간주하는 거리
- filterByArea: 면적 필터 옵션
- minArea, maxArea: min~max 범위의 면적만 BLOB으로 검출
- filterByCircularity: 원형 비율 필터 옵션
- minCircularity, maxCircularity: min~max 범위의 원형 비율만 BLOB으로 검출
- filterByColor: 밝기를 이용한 필터 옵션
- blobColor: 0 = 검은색 BLOB 검출, 255 = 흰색 BLOB 검출
- filterByConvexity: 볼록 비율 필터 옵션
- minConvexity, maxConvexity: min~max 범위의 볼록 비율만 BLOB으로 검출
- filterByInertia: 관성 비율 필터 옵션
- minInertiaRatio, maxInertiaRatio: min~max 범위의 관성 비율만 BLOB으로 검출
- minThreshold, maxThreshold, thresholdStep: BLOB를 생성하기 위한 경계 값
8.3 디스크립터 추출기
특징점이란 말 그대로 이미지에서 특징이 되는 부분을 의미합니다. 이미지끼리 서로 매칭이 되는지 확인을 할 때
각 이미지에서의 특징이 되는 부분끼리 비교를 합니다. 즉, 이미지 매칭 시 사용하는 것이 바로 특징점입니다.
특징점은 영어로 키 포인트(Keypoints)라고도 합니다.
이 특징점은 객체의 좌표뿐만 아니라 그 주변 픽셀과의 관계에 대한 정보를 가집니다.
그중 가장 대표적인 것이 size와 angle 속성이며, 코너(corner)점인 경우 코너의 경사도와 방향도 속성으로 가집니다.
특징 디스크립터(feature descriptor)란 특징점 주변 픽셀을 일정한 크기의 블록으로 나누어 각 블록에 속한 픽셀의 그레디언트 히스토그램을 계산한 것입니다.
주로 특징점 주변의 밝기, 색상, 방향, 크기 등의 정보가 포함되어 있습니다.
추출하는 알고리즘에 따라 특징 디스크립터가 일부 달라질 수는 있습니다. 일반적으로 특징점 주변의 블록 크기에 8방향(상, 하, 좌, 우 및 네 방향의 대각선) 경사도를 표현하는 경우가 많습니다.
4 x 4 크기의 블록인 경우 한 개의 특징점당 4 x 4 x 8 = 128개의 값을 갖습니다.
8.3.2 SIFT
기존의 해리스 코너 검출 알고리즘은 크기 변화에 민감한 문제를 가지고 있었습니다. SIFT는 이미지 피라미드를 이용해서 크기 변화에 따른 특징점 검출 문제를 해결한 알고리즘입니다. OpenCV에서 제공하는 SIFT 객체 생성자는 다음과 같습니다.
detector = cv2.xfeatures2d.SIFT_create(nfeatures, nOctaveLayers, contrastThreshold, edgeThreshold, sigma) nfeatures: 검출 최대 특징 수 nOctaveLayers: 이미지 피라미드에 사용할 계층 수 contrastThreshold: 필터링할 빈약한 특징 문턱 값 edgeThreshold: 필터링할 엣지 문턱 값 sigma: 이미지 피라미드 0 계층에서 사용할 가우시안 필터의 시그마 값
OpenCV는 특징 디스크립터를 추출하기 위해 다음과 같은 함수를 제공합니다.
keypoints, descriptors = detector.compute(image, keypoins, descriptors) : 특징점을 전달하면 특징 디스크립터를 계산해서 반환
keypoints, descriptors = detector.detectAndCompute(image, mask, decriptors, useProvidedKeypoints) : 특징점 검출과 특징 디스크립터 계산을 한 번에 수행
- image: 입력 이미지
- keypoints: 디스크립터 계산을 위해 사용할 특징점
- descriptors(optional): 계산된 디스크립터
- mask(optional): 특징점 검출에 사용할 마스크
- useProvidedKeypoints(optional): True인 경우 특징점 검출을 수행하지 않음
이전 chapter에서 소개했던 각종 특징점 검출기를 통해 특징점을 검출한 경우에는 detector.compute() 함수를 사용해서 특징 디스크립터를 구할 수 있습니다.
detector.compute() 함수의 keypoints 파라미터에 특징점을 전달해주면 됩니다. 반면 detector.detectAndCompute() 함수는 특징점과 특징 디스크립터를 동시에 계산해줍니다.
따라서 특징점 검출기로 특징점을 한번 검출하고, 그다음 detector.compute() 함수를 사용하는 것보다 처음부터 detector.detectAndCompute() 함수를 사용하는 게 더 편리하겠죠.
이제 소개할 SIFT, SURF, ORB는 모두 특징 디스크립터를 구해주는 알고리즘입니다.
8.3.3 SURF
SIFT는 크기 변화에 따른 특징 검출 문제를 해결하기 위해 이미지 피라미드를 사용하므로 속도가 느리다는 단점이 있습니다.
SURF는 이미지 피라미드 대신 필터의 크기를 변화시키는 방식으로 성능을 개선한 알고리즘입니다.
SURF는 아래와 같이 생성할 수 있습니다.
detector = cv2.xfeatures2d.SURF_create(hessianThreshold, nOctaves, nOctaveLayers, extended, upright)
- hessianThreshold(optional): 특징 추출 경계 값
- default=100
- nOctaves(optional): 이미지 피라미드 계층 수
- default=3
- extended(optional): 디스크립터 생성 플래그
- default=False
- True: 128개
- False: 64개
- upright(optional): 방향 계산 플래그
- default=False
- True: 방향 무시
- False: 방향 적용
8.3.4 ORB
디스크립터 검출기 중 BRIEF(Binary Robust Independent Elementary Features)라는 것이 있습니다.
BRIEF는 특징점 검출은 지원하지 않는 디스크립터 추출기입니다.
이 BRIEF에 방향과 회전을 고려하도록 개선한 알고리즘이 바로 ORB입니다.
이 알고리즘은 특징점 검출 알고리즘으로 FAST를 사용하고 회전과 방향을 고려하도록 개선했으며 속도도 빨라 SIFT와 SURF의 좋은 대안으로 사용됩니다.
ORB 객체 생성은 다음과 같이 합니다.
detector = cv2.ORB_create(nfeatures, scaleFactor, nlevels, edgeThreshold, firstLevel, WTA_K, scoreType, patchSize, fastThreshold)
- nfeatures(optional): 검출할 최대 특징 수
- default=500
- scaleFactor(optional): 이미지 피라미드 비율
- default=1.2
- nlevels(optional): 이미지 피라미드 계층 수
- default=8
- edgeThreshold(optional): 검색에서 제외할 테두리 크기, patchSize와 맞출 것
- default=31
- firstLevel(optional): 최초 이미지 피라미드 계층 단계
- default=0
- WTA_K(optional): 임의 좌표 생성 수 (default=2)
- scoreType(optional): 특징점 검출에 사용할 방식
- cv2.ORB_HARRIS_SCORE: 해리스 코너 검출(default)
- cv2.ORB_FAST_SCORE: FAST 코너 검출
- patchSize(optional): 디스크립터의 패치 크기
- default=31
- fastThreshold(optional): FAST에 사용할 임계 값
- default=20
ORB를 활용해 특징점 및 특징 디스크립터를 검출해보겠습니다.
8.4 특징 매칭
8.4.1 특징 매칭 인터페이스
특징 매칭이란 서로 다른 두 이미지에서 특징점과 특징 디스크립터들을 비교해서 비슷한 객체끼리 짝짓는 것을 말합니다.
OpenCV는 특징 매칭을 위해 아래와 같은 특징 매칭 인터페이스 함수를 제공합니다.
matcher = cv2.DescriptorMatcher_create(matcherType) : 매칭기 생성자
- matcherType: 생성할 구현 클래스의 알고리즘
- BruteForce: NORM_L2를 사용하는 BFMatcher
- BruteForce-L1: NORM_L1을 사용하는 BFMatcher
- BruteForce-Hamming: NORM_HAMMING을 사용하는 BRMatcher
- BruteForce-Hamming(2): NORM_HAMMING2를 사용하는 BFMatcher,
- FlannBased: NORM_L2를 사용하는 FlannBasedMatcher
OpenCV 3.4에서 제공하는 특징 매칭기는 BFMatcher와 FLannBasedMatcher가 있습니다.
객체를 생성하기 위해 해당 클래스의 생성자를 호출해도 되지만 cv2.DescriptorMatcher_create()의 파라미터로 구현할 클래스의 알고리즘을 문자열로 전달해주어도 됩니다.
cv2.DescriptorMatcher_create() 함수를 통해 생성된 특징 매칭기는 두 개의 디스크립터를 서로 비교하여 매칭 해주는 함수를 갖습니다.
3개의 함수가 있는데, match(), knnMatch(), radiusMatch()가 그것입니다. 세 함수 모두 첫 번째 파라미터인 queryDescriptors를 기준으로 두 번째 파라미터인 trainDescriptors에 맞는 매칭을 찾습니다.
matches = matcher.match(queryDescriptors, trainDescriptors, mask) : 1개의 최적 매칭
- queryDescriptors: 특징 디스크립터 배열, 매칭의 기준이 될 디스크립터
- trainDescriptors: 특징 디스크립터 배열, 매칭의 대상이 될 디스크립터
- mask(optional): 매칭 진행 여부 마스크
- matches: 매칭 결과, DMatch 객체의 리스트
matches = matcher.knnMatch(queryDescriptors, trainDescriptors, k, mask, compactResult) : k개의 가장 근접한 매칭
- k: 매칭할 근접 이웃 개수
- compactResult(optional): True: 매칭이 없는 경우 매칭 결과에 불포함
- default=False
matches = matcher.radiusMatch(queryDescriptors, trainDescriptors, maxDistance, mask, compactResult) : maxDistance 이내의 거리 매칭
- maxDistance: 매칭 대상 거리
match() 함수는 queryDescriptors 한 개당 최적의 매칭을 이루는 trainDescriptors를 찾아 결과로 반환합니다.
그러나 최적 매칭을 찾지 못하는 경우도 있기 때문에 반환되는 매칭 결과 개수가queryDescriptors의 개수보다 적을 수도 있습니다.
knnMatch() 함수는 queryDescriptors 한 개당 k개의 최근접 이웃 개수만큼 trainDescriptors에서 찾아 반환합니다.
k는 세 번째 파라미터입니다. k개의 최근접 이웃 개수만큼이라는 말은 가장 비슷한 k개만큼의 매칭 값을 반환한다는 뜻입니다.
CompactResult에 default값이 False가 전달되면 매칭 결과를 찾지 못해도 결과에 queryDescriptors의 ID를 보관하는 행을 추가합니다.
True가 전달되면 아무것도 추가하지 않습니다.
radiusMatch() 함수는 queryDescriptors에서 maxDistance 이내에 있는 trainDescriptors를 찾아 반환합니다.
위 세 함수인 match(), knnMatch(), radiusMatch() 함수의 반환 결과는 DMatch 객체 리스트입니다.
- DMatch: 매칭 결과를 표현하는 객체
- queryIdx: queryDescriptors의 인덱스
- trainIdx: trainDescriptors의 인덱스
- imgIdx: trainDescriptor의 이미지 인덱스
- distance: 유사도 거리
DMatch 객체의 queryIdx와 trainIdx로 두 이미지의 어느 지점이 서로 매칭 되었는지 알 수 있습니다. 또한 distnace로 얼마나 가까운 거리 인지도 알 수 있습니다.
매칭 결과를 시각적으로 표현하기 위해 두 이미지를 하나로 합쳐서 매칭점끼리 선으로 연결하는 작업이 필요한데, 이를 위해 OpenCV에서는 아래의 함수를 제공합니다.
cv2.drawMatches(img1, kp1, img2, kp2, matches, flags) : 매칭점을 이미지에 표시
- img1, kp1: queryDescriptor의 이미지와 특징점
- img2, kp2: trainDescriptor의 이미지와 특징점 matches: 매칭 결과
- flags: 매칭점 그리기 옵션
- cv2.DRAW_MATCHES_FLAGS_DEFAULT: 결과 이미지 새로 생성(default값),
- cv2.DRAW_MATCHES_FLAGS_DRAW_OVER_OUTIMG: 결과 이미지 새로 생성 안 함,
- cv2.-DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS: 특징점 크기와 방향도 그리기,
- cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS: 한쪽만 있는 매칭 결과 그리기 제외
8.4.2 BFMatcher
Brute-Force 매칭기는 queryDescriptors와 trainDescriptors를 하나하나 확인해 매칭되는지 판단하는 알고리즘으로 OpenCV에서는 cv2.BFMatcher 클래스로 제공합니다.
Brute-Force 매칭기는 아래와 같이 생성합니다.
matcher = cv2.BFMatcher_create(normType, crossCheck)
- normType: 거리 측정 알고리즘
- cv2.NORM_L1
- cv2.NORM_L2(default)
- cv2.NORM_L2SQR, cv2.NORM_HAMMING
- cv2.NORM_HAMMING2
- crossCheck: 상호 매칭이 되는 것만 반영
- default=False
거리 측정 알고리즘을 전달하는 파라미터인 normType의 값은 다음과 같이 계산합니다.

세 가지 유클리드 거리 측정법과 두 가지 해밍 거리 측정법 중에 선택을 할 수 있습니다.
SIFT와 SURF 디스크립터 검출기의 경우 NORM_L1, NORM_L2가 적합하고 ORB로 디스크립터 검출기의 경우 NORM_HAMMING이 적합하며, NORM_HAMMING2는 ORB의 WTA_K가 3 혹은 4일 때 적합하다고 합니다.
crossCheck가 True이면 양쪽 디스크립터 모두에게서 매칭이 완성된 것만 반영하므로 불필요한 매칭을 줄일 수 있지만 그만큼 속도가 느려진다는 단점이 있습니다.
8.4.3 FLANN
BFMatcher는 모든 디스크립터를 전수 조사하므로 이미지 사이즈가 클 경우 속도가 굉장히 느립니다.
이를 해결하기 위해 FLANN을 사용할 수 있습니다. FLANN은 모든 디스크립터를 전수 조사하기 보다 이웃하는 디스크립터끼리 비교를 합니다.
이웃하는 디스크립터를 찾기 위해 FLANN 알고리즘 함수에 인덱스 파라미터와 검색 파라미터를 전달해야 합니다.
OpenCV는 FLANN 객체 생성을 위한 함수로 cv2.FlannBasedMatcher()를 제공합니다.
이 함수는 인덱스 파라미터로 indexParams를 전달받고 검색 파라미터로 searchParams를 전달받습니다.
두 파라미터 모두 딕셔너리 형태입니다.
matcher = cv2.FlannBasedMatcher(indexParams, searchParams)
파라미터로 전달 받는 인덱스 파라미터와 검색 파라미터는 다음과 같은 값을 갖습니다.
- indexParams: 인덱스 파라미터 (딕셔너리)
- algorithm: 알고리즘 선택 키, 선택할 알고리즘에 따라 종속 키를 결정하면 됨
- FLANN_INDEX_LINEAR=0: 선형 인덱싱, BFMatcher와 동일
- FLANN_INDEX_KDTREE=1: KD-트리 인덱싱 (trees=4: 트리 개수(16을 권장))
- FLANN_INDEX_KMEANS=2: K-평균 트리 인덱싱 (branching=32: 트리 분기 개수, iterations=11: 반복 횟수, centers_init=0: 초기 중심점 방식)
- FLANN_INDEX_COMPOSITE=3: KD-트리, K-평균 혼합 인덱싱 (trees=4: 트리 개수, branching=32: 트리 분기 새수, iterations=11: 반복 횟수, centers_init=0: 초기 중심점 방식)
- FLANN_INDEX_LSH=6: LSH 인덱싱
- table_number: 해시 테이블 수
- key_size: 키 비트 크기,
- multi_probe_level: 인접 버킷 검색
- FLANN_INDEX_AUTOTUNED=255: 자동 인덱스
- target_precision=0.9: 검색 백분율
- build_weight=0.01: 속도 우선순위
- memory_weight=0.0: 메모리 우선순위
- sample_fraction=0.1: 샘플 비율) searchParams: 검색 파라미터 (딕셔너리)
- algorithm: 알고리즘 선택 키, 선택할 알고리즘에 따라 종속 키를 결정하면 됨
- searchParams: 검색 파라미터 (딕셔너리)
- checks=32: 검색할 후보 수
- eps=0.0: 사용 안 함
- sorted=True: 정렬해서 반환
인덱스 파라미터는 결정해야 할 값이 너무 많아 복잡합니다. 그래서 아래와 같이 설정하는 것을 권장합니다.
<SIFT나 SURF를 사용하는 경우>
- FLANN_INDEDX_KDTREE = 1
- index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
<ORB를 사용하는 경우>
- FLANN_INDEX_LSH = 6
- index_params = dict(algorithm=FLANN_INDEX_LSH, table_number=6, key_size=12, multi_probe_level=1)
8.4.4 좋은 매칭점 찾기
이전 포스팅에서 match(), knnMatch(), radiusMatch() 함수를 활용하여 매칭점을 찾는 실습을 했습니다.
그러나 잘못된 매칭 결과가 굉장히 많이 포함되어 있었습니다.
매칭 결과에서 쓸모없는 매칭점은 버리고 올바른 매칭점만 골라내는 작업이 필요합니다. 만약
올바른 매칭점만 남겼는데 매칭점이 몇 개 없다면 두 이미지는 서로 연관관계가 없다고 판단해야 합니다.
radiusMatch()는 maxDistance 파라미터를 조절하는 것 말고는 큰 의미가 없으므로 제외하고, match()와 knnMatch() 함수를 활용해 올바른 매칭점을 찾는 방법에 대해 알아보겠습니다.
match() 함수는 모든 디스크립터를 하나하나 비교하여 매칭점을 찾습니다. 따라서 가장 작은 거리 값과 큰 거리 값의 상위 몇 퍼센트만 골라서 올바른 매칭점을 찾을 수 있습니다.
아래는 match() 함수를 통해 올바른 매칭점을 찾는 코드입니다. ORB로 디스크립터를 추출하고 BF-Hamming 매칭기로 매칭을 계산했습니다. 매칭 결과의 거리(distance)를 기준으로 정렬하고 거리가 짧은 20%의 매칭점만 골랐습니다.
8.4.5 매칭 영역 원근 변환
올바르게 매칭된 좌표들에 원근 변환 행렬을 구하면 매칭 되는 물체가 어디 있는지 표시할 수 있습니다. 위에서 실습했던 이미지를 보겠습니다. 찾고자 하는 물체는 로봇 태권 V입니다.
두 사진에서 로봇 태권 V의 크기, 방향, 색상 등이 거의 동일합니다만 조금 다릅니다.
비교하려는 물체가 두 사진 상에서 약간 회전했을 수도 있고 크기가 조금 다를 수도 있습니다.
이에 대해 원근 변환 행렬을 구하면 찾고자 하는 물체의 위치를 잘 찾을 수 있습니다. 더불어 원근 변환 행렬에 들어맞지 않는 매칭점을 구분할 수 있어서 나쁜 매칭점을 한번 더 제거할 수 있습니다.
여러 매칭점으로 원근 변환 행렬을 구하는 함수는 cv2.findHomography()이고, 원래 좌표들을 원근 변환 행렬로 변환하는 함수는 cv2.perspectiveTransform()입니다.
mtrx, mask = cv2.findHomography(srcPoints, dstPoints, method, ransacReprojThreshold, mask, maxIters, confidence)
- srcPoints: 원본 좌표 배열
- dstPoints: 결과 좌표 배열
- method=0(optional): 근사 계산 알고리즘 선택
- 0: 모든 점으로 최소 제곱 오차 계산
- cv2.RANSAC
- cv2.LMEDS
- cv2.RHO
- ransacReprojThreshold=3(optional): 정상치 거리 임계 값(RANSAC, RHO인 경우)
- maxIters=2000(optional): 근사 계산 반복 횟수
- confidence=0.995(optional): 신뢰도(0~1의 값)
- mtrx: 결과 변환 행렬
- mask: 정상치 판별 결과, N x 1 배열 (0: 비정상치, 1: 정상치)
dst = cv2.perspectiveTransform(src, m, dst)
- src: 입력 좌표 배열
- m: 변환 배열
- dst(optional): 출력 좌표 배열
cv2.findHomography() 함수는 cv2.getPerspectiveTransform() 함수와 비슷합니다. 다만 cv2.getPerspectiveTransform()은 4개의 꼭짓점으로 정확한 원근 변환 행렬을 반환하지만, cv2.findHomography()는 여러 개의 점으로 근사 계산한 원근 변환 행렬을 반환합니다. cv2.perspectiveTransform() 함수는 원근 변환할 새로운 좌표 배열을 반환합니다.
cv2.findHomography() 함수의 method 파라미터에는 0, cv2.RANSAC, cv2.LMEDS, cv2.RHO의 값을 전달할 수 있습니다. 이는 원근 변환의 근사 계산을 위한 알고리즘입니다. default 값인 0은 모든 좌표를 최소 제곱 법으로 근사 계산합니다. 이는 모든 좌표에 대해 계산되므로 틀린 매칭점이 있다면 오차가 클 수 있습니다.
method 파라미터에 cv2.RANSAC를 전달하면 RANSAC(Random Sample Consensus) 알고리즘을 사용합니다. 이는 모든 좌표를 사용하지 않고 임의의 좌표만 선정해서 만족도를 구하는 방식인데, 이렇게 구한 만족도가 큰 것만 선정하여 근사 계산합니다. 선정된 점들은 정상치로 분류하고 그 외의 점들은 이상치로 분류해서 노이즈로 판단합니다. 이때 이상치를 구분하는 임계 값으로 ransacReprojThreshold 값을 정하면 됩니다. 변환 값은 결과 변환 행렬(mtrx)과 정상치 판별 결과(mask)입니다. mask에는 입력 좌표와 동일한 인덱스에 정상치는 1, 이상치는 0으로 표시됩니다. 이는 올바른 매칭점과 나쁜 매칭점을 구분하는데 활용할 수 있습니다. 특징 매칭을 하더라도 올바르지 않은 매칭점들이 굉장히 많다는 걸 이전 포스팅에서 살펴봤습니다. 하지만 cv2.RANSAC을 활용한다면 정상치와 이상치를 구분해주는 mask를 반환하므로 올바른 매칭점과 나쁜 매칭점을 한번 더 구분할 수 있습니다.
method 파라미터에 cv2.LMEDS를 전달하면 LMedS(Least Median of Squares) 알고리즘을 활용하여 제곱의 최소 중간값을 사용합니다. 이 알고리즘은 추가적인 파라미터를 요구하지 않아 사용하기에는 편하지만, 정상치가 50% 이상인 경우에만 정상적으로 작동하니 주의할 필요가 있습니다.
cv2.RHO는 RANSAC을 개선한 PROSAC(Progressive Sample Consensus) 알고리즘을 사용합니다. 아 알고리즘은 이상치가 많은 경우에 더 빠릅니다.
아래 코드는 올바른 매칭점을 활용해 원근 변환 행렬을 구하고, 원본 이미지 크기만큼의 사각형 도형을 원근 변환하여 결과 이미지에 표시하는 코드입니다. 이렇게 함으로써 찾고자 하는 물체가 어디 있는지 표시할 수 있습니다.
결과 이미지에서 찾고자 하는 물체(여기서는 로봇 태권 v)가 어디 있는지 표시되었습니다.
print('good matches:%d/%d' %(len(good_matches),len(matches)))
이 부분까지는 '올바른 매칭점 찾기'에서 활용한 코드와 동일합니다.
원근 변환 행렬을 구하는 코드는 아래 부분입니다.
# 좋은 매칭점의 queryIdx로 원본 영상의 좌표 구하기 ---③
src_pts = np.float32([ kp1[m.queryIdx].pt for m in good_matches ])
# 좋은 매칭점의 trainIdx로 대상 영상의 좌표 구하기 ---④
dst_pts = np.float32([ kp2[m.trainIdx].pt for m in good_matches ])
# 원근 변환 행렬 구하기 ---⑤
mtrx, mask = cv2.findHomography(src_pts, dst_pts)우선 good_matches는 knnMatch() 함수의 반환 결과입니다.
이전 포스팅에서 살펴본 바와 같이 match(), knnMatch(), radiusMatch() 함수의 반환 결과는 DMatch 객체 리스트입니다.
- DMatch: 매칭 결과를 표현하는 객체
- queryIdx: queryDescriptors의 인덱스
- trainIdx: trainDescriptors의 인덱스
- imgIdx: trainDescriptor의 이미지 인덱스
- distance: 유사도 거리
따라서 good_matches 배열에서 하나의 원소 m에 대한 m.queryIdx 값은 입력 이미지의 디스크립터(queryDescriptors)에 해당하는 인덱스입니다.
그리하여 kp1[m.queryIdx].pt는 ORB로 추출한 모든 특징점들 중 m.queryIdx에 해당하는 특징점 좌표들만 선택한다는 뜻입니다.
이것이 바로 올바른 매칭점입니다. 입력 이미지에 대한 올바른 매칭점 src_pts와 대상 이미지에 대한 올바른 매칭점 dst_pts를 구했습니다.
올바른 매칭점인 src_pts, dst_pts를 활용하여 cv2.findHomography() 함수로 원근 변환 행렬을 구할 수 있습니다.
아래의 코드를 활용하여 원근 변환한 도형을 대상 이미지에 표시했습니다.
8.5 객체 추적
동영상에서 지속적으로 움직이는 객체를 찾는 방법을 객체 추적이라고 합니다.
객체 추적 방법은 여러 가지가 있습니다. 몇 가지만 알아보겠습니다. 이번 포스팅에서는 배경 제거에 대해 알아보겠습니다.
8.5.1 동영상 배경 제거
객체 추적을 위해 객체가 무엇인지, 어디 있는지부터 명확히 파악해야 합니다.
객체를 명확히 파악하기 위한 방법이 바로 배경 제거입니다. 배경 제거는 객체를 포함하는 영상에서 객체가 없는 배경 영상을 빼는 방법을 말합니다.
즉, 배경을 모두 제거해 객체만 남기는 방법입니다. 아래 그림을 보면 이해가 쉬울 겁니다.
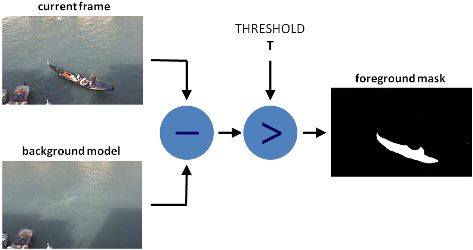
강 위에 배가 있는 영상에서 강만 있는 영상을 빼면 객체인 배만 남습니다.
배경 제거 함수 배경 제거를 구현하는 객체 생성 함수는 아래와 같습니다.
cv2.bgsegm.createBackgroundSubtractorMOG(history, nmixtures, backgroundRatio, noiseSigma)
- history=200: 히스토리 길이
- nmixtures=5: 가우시안 믹스처의 개수
- backgroundRatio=0.7: 배경 비율
- noiseSigma=0: 노이즈 강도 (0=자동)
이는 2001년 KadewTraKuPong과 Bowde의 논문(An improved adaptive background mixture model for real-time tracking with shadow detection)에 소개된 알고리즘을 구현한 함수입니다.
여러 가지 파라미터가 있지만 default 값으로 설정해도 됩니다. 추가 튜닝이 필요 없는 이상 아래의 apply() 함수 호출만으로 결과를 얻을 수 있습니다. 배경 제거 객체의 인터페이스 함수는 다음 두 가지가 있습니다.
- foregroundmask = backgroundsubtractor.apply(img, foregroundmask, learningRate)
- img: 입력 영상
- foregroundmask: 전경 마스크
- learningRate=-1: 배경 훈련 속도(0~1, -1: 자동)
- backgroundImage = backgroundsubtractor.getBackgroundImage(backgroundImage)
- backgroundImage: 훈련용 배경 이미지
cv2.bgsegm.createBackgroundSubtractorMOG() 함수를 활용하여 배경 제거 객체를 만들어, 실제 영상에서 배경을 제거해보겠습니다.
배경 제거 객체 생성시 파라미터 값은 모두 default 값으로 설정했습니다.
배경 제거 객체에 apply() 함수를 적용하여 배경이 제거된 전경 마스크를 얻었습니다.
또 다른 배경 제거 객체 생성 함수는 다음과 같습니다.
- cv2.createBackgroundSubtractorMOG2(history, varThreshold, detectShadows)
- history=500: 히스토리 개수
- varThreshold=16: 분산 임계 값
- detectShadows=True: 그림자 표시
이는 Z.Zivkovic의 2004년 논문(Improved adaptive Gausian mixture model for background subtraction)과 2006년 논문(Efficient Adaptive Density Estimation per Image Pixel for the Task of Background Subtraction)에 소개된 알고리즘을 구현한 함수입니다.
이 알고리즘은 영상의 각 픽셀에서 적절한 가우시안 분포 값을 선택합니다. 따라서 빛의 변화가 심한 영상에 적용하기 좋습니다. 또한, 그림자를 탐지할지 말지 선택할 수 있습니다.
detectShadows=True로 설정하면 그림자를 표시하고 False로 설정하면 그림자를 표시하지 않습니다. 그림자는 회색으로 표시하고, 그림자를 표시하면 속도가 다소 느려집니다.
8.5.2 옵티컬 플로
광학 흐름이란 영상 내 물체의 움직임 패턴을 말합니다. 이전 프레임과 다음 프레임 간 픽셀이 이동한 방향과 거리 분포입니다.
광학 흐름으로 영상 내 물체가 어느 방향으로 얼마만큼 움직였는지 파악할 수 있습니다. 더불어 추가 연산을 하면 물체의 움직임을 예측할 수도 있습니다.

광학 흐름은 다음 두 가지 사실을 가정합니다.
- 연속된 프레임 사이에서 움직이는 물체의 픽셀 강도(intensity)는 변함이 없다.
- 이웃하는 픽셀은 비슷한 움직임을 갖는다.
광학 흐름을 계산하는 방법은 두 가지입니다. 일부 픽셀만 계산하는 희소(sparse) 광학 흐름과 영상 전체 픽셀을 모두 계산하는 밀집(dense) 광학 흐름입니다.
루카스-카나데(Lucas-Kanade) 알고리즘 광학 흐름은 이웃하는 픽셀이 비슷하게 움직인다고 가정합니다. 루카스-카나데 알고리즘은 이 가정을 이용하는 알고리즘입니다.
이웃하는 픽셀은 비슷한 움직임을 갖는다고 생각하고 광학 흐름을 파악합니다. 루카스-카나데 알고리즘은 작은 윈도(3 x 3 patch)를 사용하여 움직임을 계산합니다. 그래서 물체 움직임이 크면 문제가 생깁니다.
윈도 크기가 작기 때문입니다. 이 문제를 개선하기 위해 이미지 피라미드를 사용합니다. 이미지 피라미드 위쪽으로 갈수록(이미지가 작아질수록) 작은 움직임은 티가 안 나고 큰 움직임은 작은 움직임 같아 보입니다. 이렇게 큰 움직임도 감지할 수 있습니다.
OpenCV는 루카스-카나데 알고리즘을 구현한 cv2.calcOpticalFlowPyrLK() 함수를 제공합니다.
- nextPts, status, err = cv2.calcOpticalFlowPyrLK(prevImg, nextImg, prevPts, nextPts, status, err, winSize, maxLevel, criteria, flags, minEigThreshold)
- prevImg: 이전 프레임 영상
- nextImg: 다음 프레임 영상
- prevPts: 이전 프레임의 코너 특징점, cv2.goodFeaturesToTrack()으로 검출
- nextPts: 다음 프레임에서 이동한 코너 특징점
- status: 결과 상태 벡터, nextPts와 같은 길이, 대응점이 있으면 1, 없으면 0
- err: 결과 에러 벡터, 대응점 간의 오차
- winSize = (21,21): 각 이미지 피라미드의 검색 윈도 크기
- maxLevel=3: 이미지 피라미드 계층 수
- criteria=(COUNT+EPS, 30, 0.01): 반복 탐색 중지 요건
- cv2.TERM_CRITERIA_EPS: 정확도가 epsilon보다 작으면 중지
- cv2.TERM_CRITERIA_MAX_ITER: max_iter 횟수를 채우면 중지
- cv2.TERM_CRITERIA_COUNT: MAX_ITER와 동일, max_iter: 최대 반복 횟수, epsilon: 최소 정확도
- flgs=0: 연산 모드
- 0: prevPts를 nextPts의 초기 값으로 사용
- cv2.OPTFLOW_USE_INITAL_FLOW: nextPts의 값을 초기 값으로 사용
- cv2.OPTFLOW_LK_GET_MIN_EIGENVALS: 오차를 최소 고유 값으로 계산
- minEigThreshold=1e-4: 대응점 계산에 사용할 최소 임계 고유 값
위 함수는 영상 내 픽셀 전체를 한번에 계산하지 않습니다. cv2.goodFeaturesToTrack() 함수로 얻은 특징점만 활용하여 계산합니다.
prevImg와 nextImg 파라미터에는 이전 프레임과 다음 프레임을 전달하면 됩니다.
prevPts 파라미터에는 이전 프레임에서 얻은 특징점을 전달합니다. 그러면 특징점이 다음 프레임에서 어디로 이동했는지 계산하여 nextPts로 반환합니다.
두 특징점이 서로 대응하면 status 변수가 1, 그렇지 않으면 0이 됩니다. 또한, maxLevel=0이면 이미지 피라미드를 사용하지 않습니다.
다음은 calcOpticalFlowPyrLK() 함수를 활용하여 광학 흐름을 적용한 코드입니다.
cv2.goodFeatureToTrack() 함수로 이전 프레임의 특징점을 검출했습니다. cv2.calcOpticalFlowPyrLK() 함수로 광학 흐름을 계산해 다음 프레임의 특징점을 찾았습니다.
이전 프레임과 다음 프레임 특징점 중 잘 대응되는 특징점만 선별하여 선과 점으로 표시했습니다. 원본 이미지에 추적선을 합성하는 방식으로 표현했습니다. 그래야 추적선이 보입니다.
군나르 파너백(Gunner Farneback) 알고리즘 군나르 파너백 알고리즘은 밀집 방식으로 광학 흐름을 계산하는 알고리즘입니다.
위에서 설명했다시피 밀집 방식은 영상 전체의 픽셀을 활용해 광학 흐름을 계산하는 방식입니다. 이 알고리즘은 2003년 군나르 파너백의 논문(Two-Frame Motion Estimation Based on Polynomial Expansion)에 소개된 알고리즘입니다.
군나르 파너백 알고리즘을 구현하기 위해 OpenCV에서는 cv2.calOpticalFlowFarneback() 함수를 제공합니다.
flow = cv2.calcOpticalFlowFarneback(prev, next, flow, pyr_scale, levels, winsize, iterations, poly_n, poly_sigma, flags)
- prev, next: 이전, 이후 프레임 flow: 광학 흐름 계산 결과, 각 픽셀이 이동한 거리 (입력과 동일한 크기)
- pyr_scale: 이미지 피라미드 스케일 levels: 이미지 피라미드 개수
- winsize: 평균 윈도 크기
- iterations: 각 피라미드에서 반복할 횟수
- poly_n: 다항식 근사를 위한 이웃 크기, 5 또는 7
- poly_sigma: 다항식 근사에서 사용할 가우시안 시그마
- poly_n=5일 때는 1.1
- poly_n=7일 때는 1.5
- flags: 연산 모드
- cv2.OPTFLOW_USE_INITAL_FLOW: flow 값을 초기 값으로 사용
- cv2.OPTFLOW_FARNEBACK_GAUSSIAN: 박스 필터 대신 가우시안 필터 사용
밀집 광학 흐름은 희소 광학 흐름과 다르게 영상 전체 픽셀을 활용해 계산합니다.
그래서 추적할 특징점을 따로 전달할 필요가 없습니다.
다만, 전체 픽셀을 활용해 계산하므로 속도가 느립니다.
8.5.5 Tracking API
OpenCV에서는 객체 추적을 위한 Tracking API를 제공합니다. Tracking API를 이용하면 쉽게 객체 추적을 할 수 있습니다.
알고리즘 이론을 몰라도 됩니다. 추적하고자 하는 객체만 지정해주면 API가 알아서 객체를 추적해줍니다. 편리하죠? OpenCV에서 제공하는 Tracking API생성자는 아래와 같습니다. 생성자는 알고리즘에 따라 다양합니다.
- tracker = cv2.TrackerBoosting_create(): AdaBoost 알고리즘 기반
- tracker = cv2.TrackerMIL_create(): MIL(Multiple Instance Learning) 알고리즘 기반
- tracker = cv2.TrackerKCF_create(): KCF(Kernelized Correlation Filters) 알고리즘 기반
- tracker = cv2.TrackerTLD_create(): TLD(Tracking, Learning and Detection) 알고리즘 기반
- tracker = cv2.TrackerMedianFlow_create(): 객체의 전방향/역방향을 추적해서 불일치성을 측정
- tracker = cv2.TrackerGOTURN_cretae(): CNN(Convolutional Neural Networks) 기반 - OpenCV 3.4 버전에서는 버그로 동작이 안 됨
- tracker = cv2.TrackerCSRT_create(): CSRT(Channel and Spatial Reliability)
- tracker = cv2.TrackerMOSSE_create(): 내부적으로 그레이 스케일 사용
저도 각 알고리즘이 구체적으로 어떻게 동작하는지 모릅니다. 그냥 '이런 알고리즘이 있구나'하고 넘어가도 무방합니다.
생성한 Tracker는 init() 함수로 초기화할 수 있습니다. init() 함수의 파라미터로 두 가지를 전달해야 합니다. 입력 영상과 추적 대상 객체가 있는 좌표입니다.
retval = cv2.Tracker.init(img, boundingBox): Tracker 초기화
- img: 입력 영상
- boundingBox: 추적 대상 객체가 있는 좌표 (x, y)
초기화 후 새로운 영상 프레임에서 추적 대상 객체의 위치를 찾기 위해 update() 함수를 호출해야 합니다.
retval, boundingBox = cv2.Tracker.update(img) : 새로운 프레임에서 추적 대상 객체 위치 찾기
- img: 새로운 프레임 영상
- retval: 추적 성공 여부
- boundingBox: 새로운 프레임에서의 추적 대상 객체의 새로운 위치 (x, y, w, h)
'(두산로보틱스) ROKEY 부트 캠프 > Computer Vision 교육' 카테고리의 다른 글
| ep.41 신경망학습, 오차역전파법 (0) | 2024.09.03 |
|---|---|
| ep.40 퍼셉트론, 신경망 (0) | 2024.09.02 |
| ep.38 OpenCV4 (0) | 2024.08.29 |
| ep.37 OpenCV3 (0) | 2024.08.28 |
| ep.36 OpenCV2 (0) | 2024.08.27 |



