
printf("ho_tari\n");
Final Project (Deep Fake Detection on Videos) 본문
- 목적 / 개요
“Real Video(원본 영상)과 Fake Video(deep fake가 적용된 영상)들을 명확하게 구분할 수 있는가”
‘Deep Fake 기술을 이용하여 딥보이스 범죄’, etc
- 데이터
Kaggle Competition에 존재하는 deep fake 관련 영상들 다운로드

다운로드한 원본 영상 pre-processing 진행 (Real Video 1000개, Fake Video 1000개 수집)
OpenCV를 활용하여 각 영상들의 사람 얼굴만을 보이도록 112 x 112 x 3 크기로 자르고 영상 프레임을 300에서 150으로 줄여 영상 길이를 10초에서 4초 정도로 축소


- 모델
< ResNet50 + LSTM (초기 모델) >

기존 CNN은 이미지 하나에 대해서만 deep fake인지 판별해주지만 동영상의 움직임을 통해서 미세한 노이즈를 포착하기 위해서 LSTM 사용
< Conv3D (skip connection) + LSTM >


ResNet50을 사용했을 때 정확도가 높게 나오지 않아 더 높은 정확도를 얻기 위해 모델을 Conv3D로 변경하여 사용
Conv3D는 width와 height 뿐만 아니라 depth 정보도 사용할 수 있어 동영상 데이터 처리에 용이
MaxPooling, DropOut(0.25), Learning Rate (1e-5) 사용
< Conv3D (skip connection) >



LSTM이 학습이 잘 이루어지지 않아 Conv3D만 사용
LSTM layer를 사용하지 않는 대신 이전 Conv3D 모델의 capacity (hidden neuron 수)를 증가시켜 사용
MaxPooing, Dropout (0.25), Learning Rate (1e-5) 사용
- 결과
< ResNet50 + LSTM (초기 모델) >

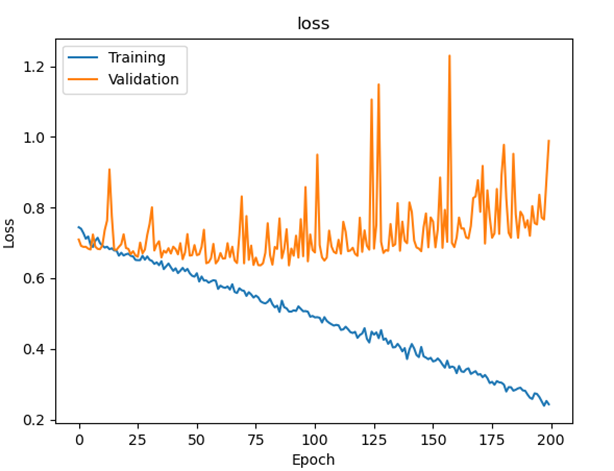
따라서, 경량화된 모델로 변경
< Conv3D (skip connection) + LSTM >



< Conv3D (skip connection) >
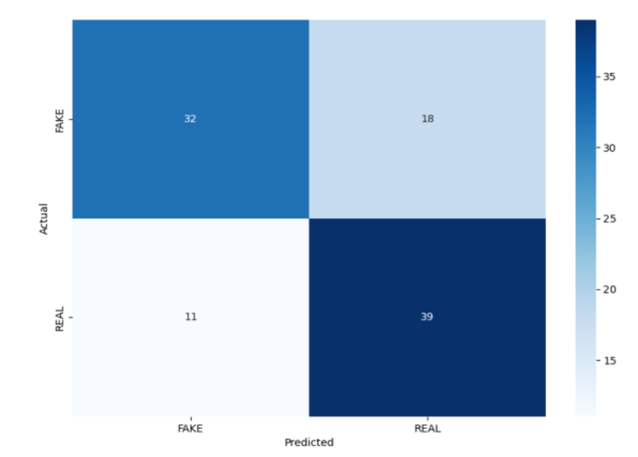

- 결론
< 프로젝트 진행 내용 최종 보고서 >



